
[Python] 2. 병렬화
본 포스팅은 “파이썬 동시성 프로그래밍” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
2-1. 동시성에 대한 이해
동시성은 한 사람이 여러 작업을 수행하고, 그 작업을 빠르게 바꾸며 진행하는 모습이라 할 수 있다. 동시성 시스템에서 다음과 같은 특징을 볼 수 있다.
- 다양한 구성: 여러 프로세서와 스레드가 각자의 작업에 모두 임하는 것. 동시에 작동되는 다수의 스레드가 있는 프로세스를 여러 개 갖고 있다.
- 자원 공유: 메모리, 디스크 등의 자원 구성이 프로그램 실행에 활용돼야 한다.
- 규칙: 모든 동시성 시스템이 락을 획득하고, 메모리에 접근하고, 상태를 변경하는 등의 조건을 따라야 한다. 이런 조건은 동시성 시스템의 작동에 매우 중요하며, 이를 어길 시 프로그램에 치명적일 수 있다.
2-2. I/O 문제
입력 및 출력 정보를 처리하는데 많은 시간이 소모되는 장애를 뜻한다. I/O를 다량으로 사용하는 애플리케이션(Ex. 네트워크 요청)이 예가 될 것이다.
요청되는 데이터양이 처리되는 데이터양보다 느릴 경우 I/O 문제가 발생한다. 이러한 애플리케이션 속도를 높이려면 I/O 자체 속도를 높이거나, 더 빠른 하드웨어를 이용하여 I/O 요청을 다뤄야 한다.
다음은 페이지를 요청하고 소요 시간을 측정하는 예제이다.
import urllib.request
import time
t0 = time.time()
req = urllib.request.urlopen('http://www.example.com') # HTML 정보 가져옴
pageHtml = req.read()
print(pageHtml)
t1 = time.time()
print("Total Time To Fetch Page: {} Seconds".format(t1 - t0))
(결과) b'<!doctype html>\n<html>\n<head>\n <title>Example Domain</title>\n\n <meta charset="utf-8" />\n <meta http-equiv="Content-type" content="text/html; charset=utf-8" />\n <meta name="viewport" content="width=device-width, initial-scale=1" />\n <style type="text/css">\n body {\n background-color: #f0f0f2;\n margin: 0;\n padding: 0;\n font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;\n \n }\n div {\n width: 600px;\n margin: 5em auto;\n padding: 2em;\n background-color: #fdfdff;\n border-radius: 0.5em;\n box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);\n }\n a:link, a:visited {\n color: #38488f;\n text-decoration: none;\n }\n @media (max-width: 700px) {\n div {\n margin: 0 auto;\n width: auto;\n }\n }\n </style> \n</head>\n\n<body>\n<div>\n <h1>Example Domain</h1>\n <p>This domain is for use in illustrative examples in documents. You may use this\n domain in literature without prior coordination or asking for permission.</p>\n <p><a href="https://www.iana.org/domains/example">More information...</a></p>\n</div>\n</body>\n</html>\n'
Total Time To Fetch Page: 0.30388617515563965 Seconds
이제 다른 페이지에 링크를 걸어 인덱스가 가능하게 하자. BeautifulSoup 모듈을 사용할건데, BeautifulSoup은 HTML 정보로부터 원하는 데이터를 가져오기 쉽게 비슷한 분류의 데이터별로 나누어주는(Parsing) 파이썬 라이브러리이다.
import urllib.request
import time
from bs4 import BeautifulSoup
t0 = time.time()
req = urllib.request.urlopen('http://www.example.com')
t1 = time.time()
print("Total Time To Fetch Page: {} Seconds".format(t1-t0))
soup = BeautifulSoup(req.read(), "html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
t2 = time.time()
print("Total Execeution Time: {} Seconds".format(t2-t1))
(결과) Total Time To Fetch Page: 0.30403637886047363 Seconds
https://www.iana.org/domains/example
Total Execeution Time: 0.0029997825622558594 Seconds
2-3. 병렬화 이해하기
여러 작업을 동시에 처리하는 구성을 동시성이라 한다면, 병렬화란 여러 작업을 동시에 실행하고 계산하는 것이다. 그림 2-1의 위 그림은 동시성 문제다. 아래 그림은 병렬화 문제이다. 각 콜라 기계는 프로세싱 코어를 나타내며, 아래 그림이 바로 작업을 동시에 처리하는 병렬 처리 형태를 보여준다.
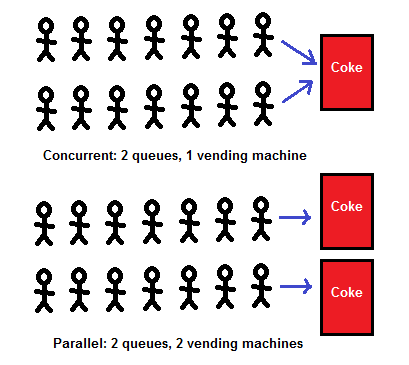
그림 2-1. 병렬화 예시
컴퓨터 그래픽 카드는 병렬화의 효과를 가장 잘 설명한다. 그래픽 카드는 독립적으로 동시에 계산하는 프로세싱 코어 개수가 수천 개이다.
2-4. CPU 제약 문제
CPU 제약 문제는 I/O 제약 문제와 그 형태가 완전 반대다. 주로 많은 숫자를 처리하거나 복잡한 계산을 수행하는 애플리케이션에서 자주 볼 수 있다. 프로그램은 실행 비율이 CPU 속도에 제약되어 있어, 고속의 CPU를 사용한다면 프로그램 속도가 바로 향상되는 것을 볼 수 있다. 즉, 처리하는 데이터가 요청되고 있는 데이터보다 많을 때 CPU 제약 문제가 발생한다.
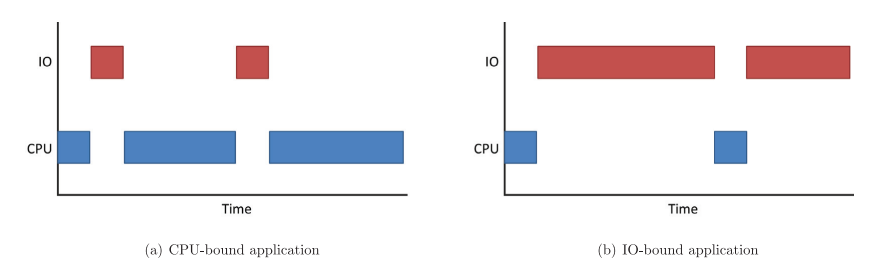
그림 2-2. CPU 제약 문제 vs I/O 제약 문제
2-5. 단일 코어 CPU
단일 코어 프로세서는 주어진 시간에 활용할 수 있는 스레드가 1개이다. 그러나 애플리케이션이 중지되거나 응답하지 않는 상황에서 프로세서는 초당 수천 번의 실행을 여러 스레드 간에 스위칭해야 한다. 이런 스레드 간 스위칭을 컨텍스트 스위치(Context switch) 라고 하며, 특정 시간에 스레드 간 필요 정보를 저장하고 나중에 그 밖의 부분에 한 번 더 저장한다.
일정하게 스레드에 저장하고 불러오는 메커니즘을 통해 주어진 시간에 여러 스레드에서 처리가 가능하며, 한 번에 많은 작업을 할 수 있다. 실제로 주어진 시간에 한 작업만 수행하지만, 그 속도를 인간이 인식하기에는 너무 빠르다.
파이썬 기반 멀티스레드 애플리케이션은 컨텍스트 스위치가 복잡한 계산 형태이며, 이를 피할 방법은 사실 없다. 그러나, 오늘날 수 많은 운영체제 디자인이 이러한 컨텍스트 스위치 형태로 최적화되고 있다.
단일 코어 CPU 장점은 다음과 같다.
1) 여러 코어들 간 복잡한 통신 프로토콜이 필요 없다.
2) 적은 전력을 소모하여 사물인터넷 제품에 적합하다.
단일 코어 CPU 단점은 다음과 같다
1) 처리 속도에 한계가 있어, 무거운 애플리케이션의 경우 느리고 동작이 멈추기도 한다.
2) 단일 코어 CPU의 작동 제한 속도에 따라 방열 문제가 발생한다.
단일 코어 애플리케이션의 가장 큰 제한은 CPU 클록 속도이다. 클록 속도를 볼 때, 초당 몇 번의 클록 사이클이 일어나는지 알아봐야 한다. 지난 10년 동안 무어의 법칙에 따라 단일 CPU 클록 속도가 급격이 증가했다. 인텔의 i7 6700k 프로세서는 약 4~5GHz의 속도를 갖는다. 그러나 트랜지스터가 나노미터 단위로 작아지면서 기술적으로 더 이상 작아질 수 없게 됐다. 이에 양자 터널 효과(DNA 굵기의 1/15 수준 정도인 전자가 터널을 오가며 정보를 저장하는 것으로, 양자 컴퓨터의 기초 기술임)가 필요해 졌으며, 기술적 한계를 맞이하게 되면서 연산 속도를 높이기 위한 여러가지 방법을 찾고 있다.
2-6. 시분할(작업 스케줄러)
운영체제의 가장 중요한 부분 중 하나로, 모든 작업을 매우 정확한 시간과 규칙에 알맞게 지시한다. 모든 작업이 완료될 때까지 실행돼야 하는 규칙도 있으나, 언제 어디에서 작업이 실행되는지 결정하지는 않는다. 이에 따라 먼저 실행되는 프로그램이 먼저 끝나지 않을 수도 있다. 이러한 비결정적 형태는 동시성 프로그램 작성을 어렵게 만든다.
다음 코드에서 비결정적인 요소를 알아보자.
import threading
import time
import random
counter = 1
def workerA():
global counter
while counter < 1000:
counter += 1
print("Worker A is incrementing counter to {}".format(counter))
sleepTime = random.randint(0, 1)
time.sleep(sleepTime)
def workerB():
global counter
while counter > -1000:
counter -= 1
print("Worker B is decrementing counter to {}".format(counter))
sleepTime = random.randint(0, 1)
time.sleep(sleepTime)
def main():
t0 = time.time()
thread1 = threading.Thread(target=workerA)
thread2 = threading.Thread(target=workerB)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
t1 = time.time()
print("Execution Time {}".format(t1-t0))
if __name__ == '__main__':
main()
(결과) Worker A is incrementing counter to 2
Worker B is decrementing counter to 1
Worker B is decrementing counter to 0
Worker B is decrementing counter to -1
Worker B is decrementing counter to -2
...
Worker B is decrementing counter to -7
Worker A is incrementing counter to -6
Worker B is decrementing counter to -7
Worker A is incrementing counter to -6
작업 A나 작업 B가 먼저 완료될 가능성도 있어 보이며, 무한히 작업 A와 작업 B 사이를 무한히 반복하며 끝내지 않을 가능성도 있어 보인다. 동기화 없이 공유 자원에 접근하려는 멀티스레드 문제도 있어 보이며, 카운터에 어떤 값이 들어갈지 정확한 방법도 없어
2-7. 멀티 코어 프로세서
멀티 코어 프로세서는 여러 개의 독립적인 유닛인 코어가 있다. 각 코어에는 저장된 인스트럭션을 처리하기 위한 요소가 있다. 코어는 다음과 같은 프로세스 형태의 사이클을 따른다.
1) 인출 단계(Fetch): 프로그램 메모리에서 인스트럭션을 인출하는 단계로, 프로그램 카운터(Program counter, PC)에서 명령받아 다음 실행 위치를 알아본다.
2) 해독 단계(Decode): 인출된 인스트럭션을 CPU의 여러 곳에서 작동하는 신호 형태로 변환한다.
3) 실행 단계(Execute): 인출되고 해독된 인스트럭션을 실행하고, 실행 결과는 CPU 레지스터에 저장된다.
멀티 코어 프로세서의 장점은 다음과 같다.
1) 단일 코어가 지닌 성능 한계가 멀티 코어에는 없다.
2) 우수하게 디자인된 애플리케이션을 멀티 코어상에서 빠른 속도로 실행할 수 있다.
멀티 코어 프로세서의 단점은 다음과 같다.
1) 일반적인 단일 코어 프로세서에 비해 많은 전력이 소모된다.
2-8. 시스템 아키텍처 스타일
프로그램을 디자인할 때, 다양한 사용 형태 범위에 따라 적합한 메모리 아키텍처 스타일이 있다. 1972년 마이클 플린이 제안한 분류치계는 컴퓨터 아키텍처를 다음 네 가지로 정의한다.
1) SISD: 단일 인스트럭션 스트림, 단일 데이터 스트림
2) SIMD: 단일 인스트럭션 스트림, 복수 데이터 스트림
3) MISD: 복수 인스트럭션 스트림, 단일 데이터 스트림
4) MIMD: 복수 인스트럭션 스트림, 복수 데이터 스트림
1. SISD
단일 프로세서 시스템에서 주로 사용된다. 하나의 데이터 스트림 입력과 이를 실행할 하나의 단일 프로세싱 유닛으로 구성된다. 모든 작업은 단일 코어 프로세서 형태로 처리하지만 인스트럭션 병렬화 및 데이터 병렬화 같은 작업 수행이 안되고, 시스템에 많은 부하를 주는 그래픽 프로세싱 또한 불가능하다.
2. SIMD
복수 데이터 스트림 형태는 많은 멀티미디어를 처리하기에 알맞은 방식이다. 벡터를 다루므로 3D 그래픽 작업 같은 부분에 이용된다. 여러 개의 벡터를 나타내는 데이터 스트림이 있고, 주어진 시간에 하나의 명령만 수행하는 프로세싱 유닛도 여러 개 존재한다. 그래픽 카드는 이러한 프로세싱 유닛이 수백 개 정도 된다.
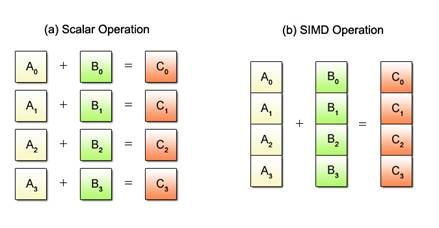
그림 2-3. SIMD 연산
SIMD의 장점은 다음과 같다.
1) 하나의 명령을 통해 동일한 연산을 다수의 엘리먼트에서 수행할 수 있다.
2) 최근 그래픽 카드상의 코어 수가 증가하면서 처리량 또한 증가하고 있다.
이러한 아키텍처 방식은 그래픽 프로세싱 장치에서 찾아볼 수 있다.
3. MISD
현재 출시된 관련 제품이 없어서 잘 알려진 아키텍처는 아니다.
4. MIMD
오늘날 멀티 코어 프로세서를 말한다. 프로세서를 구성하는 각 코어는 독립적 및 병렬적으로 작동 가능하다. SIMD와 달리 병렬적으로 복수 데이터 세트를 여러 연산으로 구별해 동작할 수 있다.
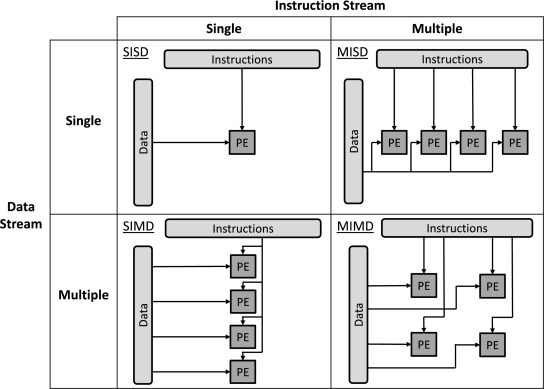
그림 2-4. SISD, SIMD, MISD, MIMD
2-9. 컴퓨터 메모리 아키텍처 스타일
동시성과 병렬화 개념에서 가장 큰 문제는 데이터에 접근하는 속도이다. 데이터에 충분히 빠르게 접근할 수 없으면 프로그램에서 병목 현상이 발생할 것이고, 아무리 디자인이 훌륭한 프로그램이어도 성능 향상이 힘들다.
성능을 높힐 수 있는 방법 중 하나는 모든 코어가 프로세서상에서 접근할 수 있는 단일 물리 주소 공간을 제공하는 것이다. 이는 복잡한 부분을 없애 코드 상의 스레드 부분에 좀 더 신경 쓸 수 있게 한다.
1. UMA(Uniform Memory Access)
균일 메모리 접근 아키텍처 스타일은 프로세싱 코어 개수에 상관없이 동일한 방식으로 공유 메모리 공간을 사용하는 것이다. 즉, 코어의 위치와 메모리와의 거리에 상관없이 동일한 시간에 직접 메모리에 접근할 수 있다.
각 프로세서는 버스를 통해 인터페이싱하며 모든 메모리에 접근하게 된다. 시스템은 또한 버스 대역폭에 부담을 준다.
UMA 장점은 다음과 같다.
1) 모든 RAM 접근은 정확한 시간에 일어난다.
2) 캐시가 일정하다.
3) 하드웨어 디자인이 간단하다.
UMA 단점은 다음과 같다.
1) 모든 시스템 접근 메모리에서 1개의 메모리 버스만 이용하므로 스케일링 문제가 나타난다(코어 개수 늘어날 때 곤란?).
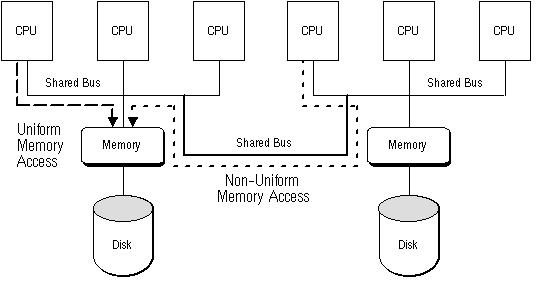
그림 2-5. UMA vs NUMA
2. NUMA(Non-Uniform Memory Access)
불균일 메모리 접근은 요청되는 프로세스에 따라 메모리 접근이 더 빠를 수 있는 아키텍처 스타일이다.(메모리 기준 프로세서의 위치 때문!)
각 프로세서는 캐시, 메인 메모리, 독립적인 입출력을 갖고 있는데, 모두 상호 연결망으로 연결됐다.
NUMA 장점은 다음과 같다.
1) 균일 메모리 접근 방식과 비교해 스케일링이 쉽다.
NUMA 단점은 다음과 같다.
1) 로컬 메모리일 경우 접근 시간이 매우 빠르나, 외부 메모리일 경우 시간이 오래 걸린다.
2) 프로세서는 그 외 프로세서에서 생긴 변화를 봐야 하는데, 주변 프로세서의 개수에 따라 그 시간이 증가할 수도 있다.
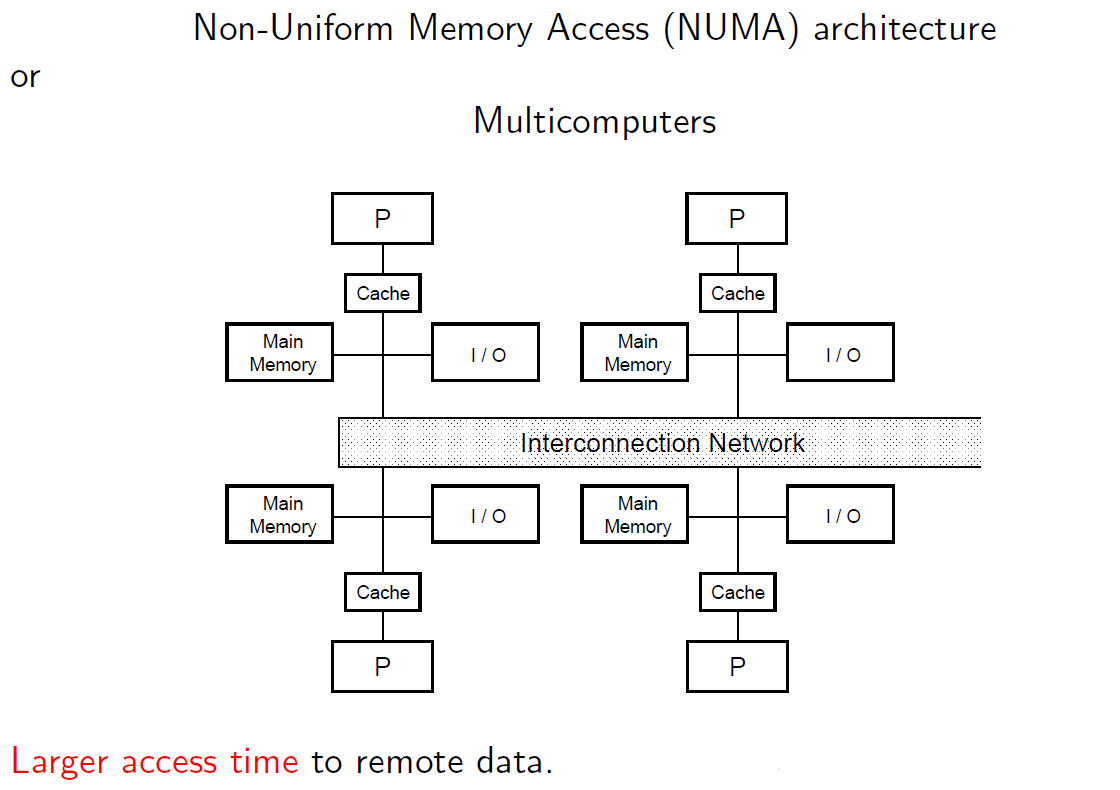
그림 2-6. NUMA
Leave a comment