
[Python] 1. 시작하기
본 포스팅은 “파이썬 동시성 프로그래밍” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
1-1. 스레드
스레드란 운영체제에서 작동되는 스케줄링될 수 있는 인스트럭션(Instruction)의 순차적인 흐름이다. 일반적으로 스레드는 프로세스에 속해 있고, 프로그램 카운터, 스택, 레지스터를 비롯해 식별자로 구성된다. 스레드는 프로세서가 시간을 할당할 수 있는 최소 단위의 실행이라고도 할 수 있다.
스레드는 공유 자원 사이에서 상호작용이 가능하고, 다수의 스레드끼리 통신도 가능하다. 메모리 공유도 가능하고 그 밖의 메모리 주소에서 읽기 및 쓰기도 가능하다. 그러나 경합 조건(Race condition) 이라는 개념 때문에, 2개의 스레드가 메모리를 공유하고 스레드의 실행 순서가 따로 정의되지 않는다면, 이상한 값이 도출되거나 시스템 충돌 문제를 야기할 수 있다.
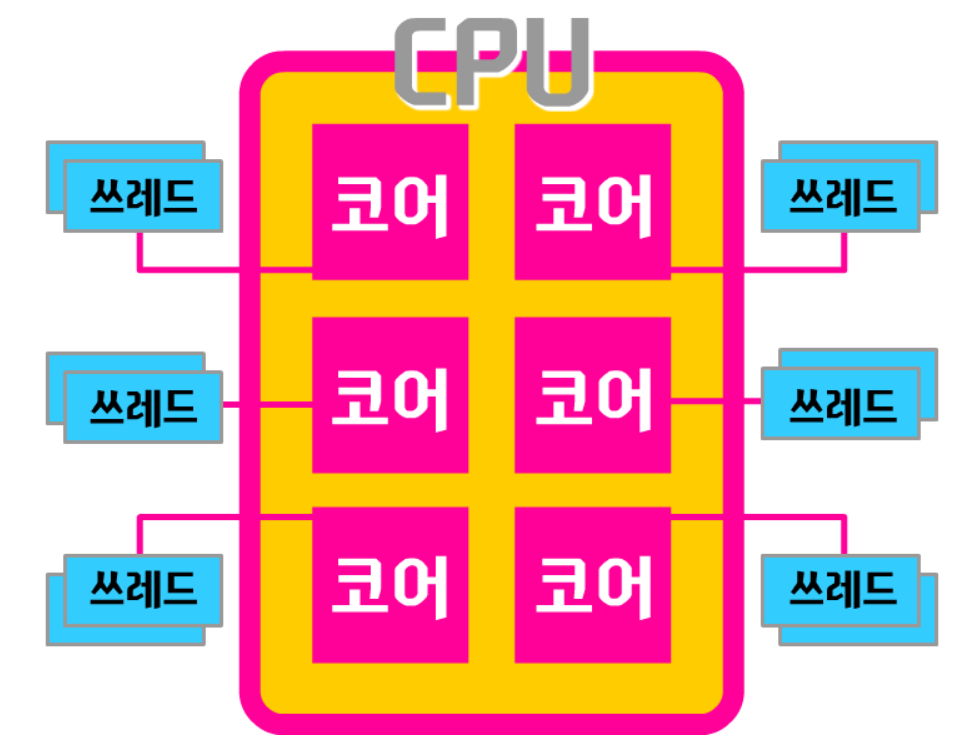
그림 1-1. 여러 스레드가 각기 다른 CPU에 있는 구조
스레드는 일반적인 운영체제에서 크게 두 가지로 구분된다.
1) 사용자 레벨 스레드: 다양한 작업에서 생성, 실행, 종료가 이뤄지는 스레드
2) 커널 레벨 스레드: 운영체제의 하위 레벨에서 실행되는 스레드
1-2 멀티스레딩
사무실에서 일어나는 상황으로 멀티스레딩을 이해해보자. 단일 스레드 프로그램은 한 사람이 모든 작업을 차례대로 처리하는 것이다. 반면, 멀티스레딩은 한 명의 작업자가 시간을 쪼개어 여러 작업을 진행하는 훌륭한 멀티태스커가 되는 것이라 볼 수 있다. 한 명의 작업자는 하나의 프로세싱 코어라 볼 수 있다. 하나의 코어로 작업을 하는 것은 여전히 한계로 작용된다. 만약 많은 업무를 병렬로 처리하고 싶다면, 더 많은 직원(프로세스)을 구해야한다.
스레딩의 장점은 다음과 같다.
1) 다수의 스레드는 입출력 범위(I/O Bound)가 막혔을 때 속도를 획기적으로 높혀준다.
2) 프로세서와 비교했을 때 메모리 조금 차지한다.
3) 스레드는 자원을 공유하므로 스레드 간 통신이 쉽다.
그러나 다음과 같은 단점도 있다.
1) Cpython 스레드는 GIL(Global Interpreter Lock)로 인해 사용에 제약이 따른다.
2) 스레드 간 통신은 쉬워졌지만, 경합 조건이 발생하지 않도록 주의해서 코드를 작성해야 한다.
3) 다수의 스레드 간 컨텍스트를 바꾸는데 수많은 계산이 필요하다. 다수의 스레드를 추가하면 전반적인 프로그램 성능이 저하되는 것을 볼 수 있다.
1-3. 프로세스
프로세스는 스레드와 비슷하지만 단일 CPU 코어에 국한되지 않는다는 점이 다르다. 다시 한번 사무실 상황에 비유하자면, 사무실을 더 크게 만들어(4코어 CPU) 2명의 영업팀 직원과 2명의 개발팀 직원을 고용하여 4명의 사람이 병렬로 업무를 처리하도록 할 수 있는 것이다.
이러한 프로세스는 하나의 주 스레드를 갖고 있다. 각 스레드마다 자체의 레지스터와 스택을 포함한 다수의 서브 스레드를 만들수도 있다.

그림 1-2. 단일 스레드 프로세스와 멀티 스레드 프로세스
프로세스를 이용하여 CPU 제약이 있거나, 더 많은 성능을 필요로 하는 특정 프로그램의 실행 속도를 높일 수 있다. 그러나 멀티프로세스로 인해 크로스 프로세스 통신(Cross-process communication) 과 관련된 문제가 발생하고, 프로세스 간 통신(IPC, Inter-process communication)에서 많은 시간을 낭비해 성능이 저하되는 문제도 발생할 수 있다.
운영체제에서 생성된 유닉스 프로세스는 다음과 같이 구성된다.
- 프로세스 ID, 프로세스 그룹 ID, 사용자 ID, 그룹 ID
- 환경
- 작업 디렉토리
- 프로그램 인스트럭션
- 레지스터
- 스택
- 힙
- 파일 기술자(File descriptor, 운영체제에서 파일 사용시 각 파일에 대한 정보를 유지하는 기억 장치의 한 영역 및 정보)
- 신호 동작
- 공유 라이브러리
- 프로세스 간 통신 도구(메시지 큐, 파이프, 세마포어, 공유 메모리)
프로세스 장점은 다음과 같다.
1) 멀티 코어 프로세서로 프로세스 성능 높일 수 있다.
2) CPU가 많이 필요한 작업에서는 멀티스레드보다 유용하다.
3) 멀티프로세스를 이용해 GIL의 한계를 피할 수 있다.
4) 프로세스의 충돌은 전체 프로그램에 영향을 주지 않는다.
프로세스 단점은 다음과 같다.
1) 프로세스 간 공유 자원이 없다(IPC 형태로 구현!).
2) 많은 메모리 필요하다.
1-4. 멀티프로세싱
오늘날 컴퓨터는 많은 CPU와 코어를 갖고 있는데, 하나의 코어만 사용하도록 제한하면 나머지 부분은 쉽게 유휴 상태가 된다. 우리는 하드웨어의 성능을 최대한 뽑아내어 효율적인 비용으로 빠르게 문제를 해결해야만 한다. 파이썬의 멀티프로세싱 모듈을 사용하면, 모든 코어와 CPU를 사용할 수 있고, CPU 집약적 문제에서 좋은 성능을 낼 수 있다.

그림 1-3. 하나의 CPU 코어가 다른 코어에게 작업 지시하는 모습
다음 코드에서 CPU 코어의 개수를 살펴볼 수 있다.
import multiprocessing
multiprocessing.cpu_count()
(결과) 8
멀티프로세싱은 하드웨어를 좀 더 활용할 수 있고, GIL이 CPython에서 문제되는 부분을 피할 수 있다. 그러나 공유되는 상태가 없고 통신도 부족하여 IPC 형태로 전달돼야 한다는 문제가 있는데, 이는 성능에 영향을 미칠 수도 있다. 공유 상태가 많지 않다는 건 코드에서 내부적 경합 조건에 신경 쓰지 않아도 된다고 볼 수 있다.
이벤트 기반 프로그래밍(Event-driven programming)은 컴퓨터의 아이콘 클릭시 운영체제가 이를 이벤트로 생각하고 관련 부분을 실행하는 것과 같다. 모든 상호작용은 이벤트 과정으로 표현할 수 있고, 일반적으로 콜백이 일어난다. 참고로 콜백이란 함수가 끝나고 난 뒤에 실행되는 함수이다. 보통 인자로 대입되는 함수를 콜백함수라고 부른다.

그림 1-4. 이벤트 기반 프로그래밍 예시
이벤트 이미터가 이벤트를 발생(구글 입사 지원서 신청)시키고 프로그램의 이벤트 루프는 이벤트를 가져와서 미리 정의된 이벤트 핸들러와 매치시킨다. 그럼 매치된 이벤트 핸들러가 이벤트를 처리하기 위해 수행(상대 이메일 주소를 전달하여 이메일로 연락)된다.
1-5. 파이썬의 한계
GIL은 병렬 파이썬 코드를 실행할 때 여러 스레드의 사용을 제한하는 상호 배제 락(Mutual exclusion lock, 여러 개의 병렬 프로세스가 공통의 변수 및 자원에 액세스할 때 임의의 시점에서 하나의 프로세스만 액세스하도록 제어하는 것)이다. 즉, 한 번에 1개의 스레드만 유지하는 락이다. 스레드를 자체 코드에서 실행하려면 자체 코드를 실행하기 전 락을 먼저 점유해야 한다. 이로 인해 락 되어 있는 동안 모든 실행이 불가능하다.

그림 1-5. GIL 설명 그림
그림 1-5를 보면, 각 스레드는 다음 작업을 진행하기 전 GIL을 기다리고 받아야 하며, 작업 완료 전 GIL을 해제해야 한다. 무작위 라운드 로빈(스케줄링의 한 방법으로, 다중 처리에서 사이클릭 방식으로 작업 처리) 방식을 이용하고, 어떤 스레드가 락을 먼저 점유할지 알 수 없다.
이게 왜 중요할까? GIL은 스레드가 없는 파이썬 메모리 관리를 방지하고자 구현됐다. 특정 멀티프로세서 시스템 구성의 약점도 막을 수 있다. GIL을 제거하려는 노력은 몇 번 있었으나 안정적인 스레드를 보장하는 락의 추가가 2배 이상의 성능 감소로 이어졌다. 즉 2개 이상의 CPU보다 1개의 CPU를 통한 작업이 더 불리하다는 것이다.
그럼에도 왜 파이썬을 사용해야 할까? 그 이유는 최고의 작업 능력을 보여주고, 복잡한 컴퓨터 연산 작업도 신속하게 처리하기 때문이다.
1-6. (예제) 멀티프로세싱으로 소인수 찾기
1) 순차적으로 소인수 구하기
import time
import random
def calculatePrimeFactors(n):
primfac = []
d = 2
while d*d <= n:
while (n % d) == 0:
primfac.append(d)
n //= d
d += 1
if n > 1:
primfac.append(n)
return primfac
def main():
print("Starting number crunching")
t0 = time.time()
for i in range(10000):
rand = random.randint(20000, 100000000)
print(calculatePrimeFactors(rand))
t1 = time.time()
totalTime = t1 - t0
print("Execution Time: {}".format(totalTime))
if __name__ == '__main__':
main()
(결과) Execution Time: 5.934545040130615
2) 동시에 소인수 구하기
import time
import random
from multiprocessing import Process
# 주어진 n에 관한 모든 소인수 구함
def calculatePrimeFactors(n):
primfac = []
d = 2
while d*d <= n:
while(n % d) == 0:
primfac.append(d)
n //= d
d += 1
if n > 1:
primfac.append(n)
return primfac
# 10000번의 계산 작업을 1000번씩 10개로 쪼개어 처리
def executeProc():
for i in range(1000):
rand = random.randint(2000, 100000000)
print(calculatePrimeFactors(rand))
def main():
print("Starting number crunching")
t0 = time.time()
procs = []
# 프로세스 생성 후 실행
for i in range(10):
proc = Process(target=executeProc, args=())
procs.append(proc)
proc.start()
# 모든 프로세스가 종료할 때까지 대기하도록 .join() 메소드 사용
for proc in procs:
proc.join()
t1 = time.time()
totalTime = t1 - t0
# 10번의 procs에 소요된 시간 출력
print("Execution Time: {}".format(totalTime))
if __name__ == '__main__':
main()
(결과) Execution Time: 0.8280038833618164
Leave a comment