
[Machine learning] 5. 선형회귀
본 포스팅은 “혼자 공부하는 머신러닝+딥러닝” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
5-1. K-최근접 이웃의 한계
이전 문제에서 길이가 훨씬 더 긴 농어에 대한 무게를 구해보자.
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=3)
knr.fit(train_input, train_target)
print(knr.predict([[50]]))
(결과) [1033.33333333]
실제 이 농어의 무게는 더 나간다고 한다. 무슨 문제가 일어났고 왜 못맞췄을까? 시각화를 해보자.
import matplotlib.pyplot as plt
distances, indexes = knr.kneighbors([[50]])
plt.scatter(train_input, train_target)
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
plt.scatter(50, 1033, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
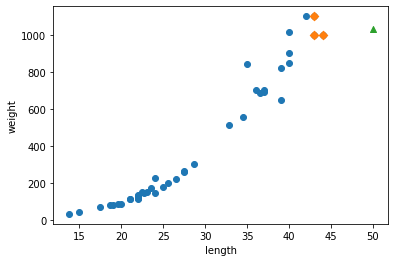
그림 5-1. 코드 결과
시각화를 하니 문제가 훤히 드러났다. 50cm 농어 근방의 샘플 3개를 평균하니 1033.3333 이 나온것이다. 새로운 샘플이 훈련 세트의 범위를 벗어나 엉뚱한 값이 예측되었다. 이건 50cm 뿐만 아니라 70cm, 100cm 농어의 무게를 구해도 똑같이 1033.3333이 나올 것이다.
이처럼 머신러닝 모델은 한 번 만들고 끝나는 프로그램이 아니다. 시간과 환경이 변화하면서 데이터도 바뀌고, 훈련 데이터에는 없는 데이터가 발생될 수도 있다. 이에 따라, 주기적으로 새로운 훈련 데이터로 모델을 다시 훈련해야 한다. 새로운 데이터를 사용하여 반복적으로 훈련하자!
5-2. 선형 회귀
일단 위에서 드러난 문제는 새로운 훈련 데이터로 재훈련하여 극복 가능하다. 그러나 훈련 데이터가 없다면? 다른 모델을 사용해야 한다. 선형 회귀는 널리 사용되는 대표적 회귀 알고리즘이다. 비교적 간단하고 성능이 뛰어나다. 특성이 하나인 경우, 훈련 데이터에 잘 맞는 어떤 직선을 학습하는 알고리즘이라 할 수 있다. 농어의 길이와 무게가 어느정도 비례하다는 것을 확인했다. 이 비례 관계를 잘 보여주는 직선을 찾자.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.predict([[50]]))
print(lr.coef_, lr.intercept_)
(결과) [1241.83860323]
[39.01714496] -709.0186449535474
선형 회귀가 K-최근접 이웃 회귀보다 50cm 농어의 무게를 더 크게 예측했다. lr 객체의 coef_와 intercept_ 속성에 직선 $y = ax + b$의 $a$와 $b$의 값이 저장되어있다. coef_와 intercept_를 모델 파라미터라고 부른다. 많은 머신러닝 알고리즘은 훈련 과정에서 최적의 모델 파라미터를 찾으려 한다. 이를 모델 기반 학습이라고 부른다. K-최근접 이웃은 모델 파라미터가 없다. 이러한 모델의 훈련법은 사례 기반 학습 이라고 한다.
한번 농어 길이 15cm ~ 50cm 까지 위의 파라미터를 이용하여 직선을 그려보자.
plt.scatter(train_input, train_target)
plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])
plt.scatter(50, 1241.8, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
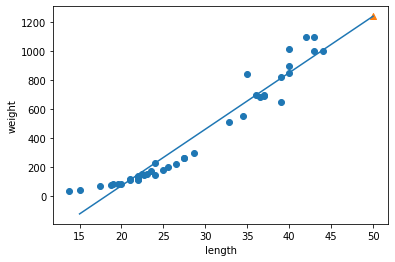
그림 5-2. 코드 결과
바로 이 직선이 선형 회귀 알고리즘이 훈련 세트에서 찾은 최적의 직선이다. $R^2$ 점수를 확인해보자.
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))
(결과) 0.9398463339976041
0.824750312331356
훈련 세트와 테스트 세트에 대한 스코어가 모두 낮은걸로 보면 과소적합인 것으로 보인다. 그런데 과소적합 말고도 다른 문제가 있다.
5-3. 다항 회귀
5-2 그림을 보면 15cm 농어에 대해서는 0g 밑으로 내려간다. 이게 말이 되는가? 사실 전체 데이터에 대한 산점도를 보면 직선 방정식이 딱 맞지도 않는다. 약간의 곡선 형태를 가지고 있는 것으로 보이니 말이다. 곡선 형태를 가지려면 2차 방정식으로 그래프를 그려야 한다. 그러려면 길이를 제곱한 특성 항이 훈련 세트에 추가되어야 한다. 앞서 배운 column_stack() 함수를 사용하여 길이에 대한 제곱 항을 만들어보자.
train_poly = np.column_stack((train_input**2, train_input))
test_poly = np.column_stack((test_input**2, test_input))
print(train_poly.shape, test_poly.shape)
(결과) (42, 2) (14, 2)
이제 train_poly 데이터로 선형 회귀 모델을 다시 훈련할 것이다. 특성이 2개가 되었으므로, $a$, $b$, $c$ 3개의 파라미터가 있을 것이고 이에 대한 최적값을 찾는 방향으로 모델이 훈련될 것이다.
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]]))
print(lr.coef_, lr.intercept_)
(결과) [1573.98423528]
[ 1.01433211 -21.55792498] 116.05021078278276
이 모델은 $무게=1.01\times 길이^{2}-21.6\times 길이+116.05$ 를 학습했다. 이런 다항식을 사용한 선형 회귀를 다항 회귀라고 부른다. 시각화를 해보자.
point = np.arange(15, 50)
plt.scatter(train_input, train_target)
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
plt.scatter(50, 1573.98, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
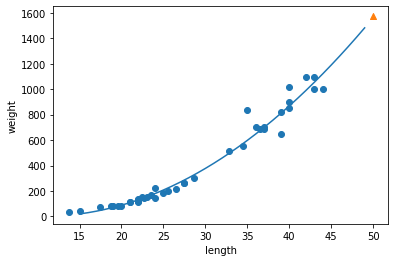
그림 5-3. 코드 결과
단순 선형 회귀보다 다항 회귀가 더 나은 그래프를 그렸다. $R^{2}$ 점수를 확인해보자.
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))
(결과) 0.9706807451768623
0.9775935108325121
선형 회귀보다 훈련 세트, 테스트 세트에 대해서는 더 높게 나왔다. 그러나 아직도 과소적합이 좀 남아있는 것으로 보인다.
Leave a comment