
[Machine learning] 2. 훈련 세트와 테스트 세트
본 포스팅은 “혼자 공부하는 머신러닝+딥러닝” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
2-1. 지도학습과 비지도학습
지도학습 알고리즘은 훈련하기 위한 데이터와 정답이 필요하다. 1장에서 훈련시킨 kn 모델이 지도학습 모델의 일종이다. 지도학습에서 데이터와 정답을 각각 입력과 타깃 이라 한다. 그리고 이 둘을 합쳐 훈련데이터 라고 한다. 1장에서 입력으로 사용했던 데이터의 길이와 무게를 특성이라 한다.
지도학습은 타깃을 활용하여 정답을 맞힐 수 있도록 학습한다. 반대로, 비지도학습 알고리즘은 타깃 없이 입력 데이터만을 사용한다. 타깃이 없기 때문에 무언가를 맞히는 학습은 불가능하다. 그 대신 데이터를 잘 파악하거나 변형하는데 도움을 줄 수 있도록 학습할 수 있다.
2-2. 훈련 세트와 테스트 세트
훈련데이터를 통해 모델을 학습시켰다. 그럼 이 모델의 성능을 평가하려면 훈련데이터 그대로 주는게 맞는걸까?
수능시험을 생각해보자. 학생들의 학업 능력을 평가하는 시험에, 시중 문제집의 문제가 그대로 나왔다. 이 문제를 풀어본 사람은 당연히 맞출 확률이 높을 것이고, 그렇지 않는 사람은 맞출 확률이 상대적으로 적을 것이다. 이 문제에 투자한 시간도 더 오래걸려 다른 문제 푸는 시간을 확보하는데에도 분명 영향을 끼칠 것이다. 이러한 이유로 연습 문제와 시험 문제는 당연히 달라야한다.
마찬가지로 머신러닝 모델을 훈련할 때, 훈련데이터와 테스트데이터를 다르게 주어야 한다!
평가에 사용하는 데이터를 테스트 세트라고 하며, 훈련에 사용되는 데이터를 훈련 세트 라고 한다. 테스트 세트를 준비할 때에는 별도의 데이터를 준비하거나, 이미 준비된 데이터 중 일부를 떼어 내어 활용한다.
배운대로 아래 데이터에서 훈련 세트와 테스트 세트를 분리시켜보자. 일단 기본 재료들을 세팅해보자.
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
fish_data = [[l, w] for l, w in zip(fish_length, fish_weight)]
fish_target = [1]*35 + [0]*14
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
fish_data에서 하나의 생선 데이터를 샘플 이라고 부른다. 총 49개의 샘플을 가지고 있다. 이 중, 35개를 훈련 세트, 나머지 14개를 테스트 세트로 사용할 것이다.
일단 파이썬 리스트의 기본 기능을 배워보자. 리스트 중 배열의 위치, 즉 인덱스라는 녀석이 있다. 그리고 슬라이싱이라는 연산자도 있다. 이들을 이용하여 리스트 안에 있는 특정 샘플들을 긁어올 수 있다.
print(fish_data[4])
print(fish_data[0:5]) # 마지막 인덱스의 원소는 포함되지 않음
print(fish_data[:5]) # 0 생략하고 쓸 수 있음
print(fish_data[44:]) # 45번째 부터 49번째 데이터 긁어옴
(결과) [29.0, 430.0]
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0]]
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0]]
[[12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
자 그럼 처음 35개의 데이터를 훈련 세트, 그 외 14개 데이터를 테스트 세트로 써서 kn 객체를 훈련시키고 모델 성능을 평가해보자.
train_input = fish_data[:35]
train_target = fish_target[:35]
test_input = fish_data[35:]
test_target = fish_target[35:]
kn = kn.fit(train_input, train_target)
kn.score(test_input, test_target)
(결과) 0.0
스코어가 0.0 이라면 하나도 못맞췄다는 소리다. 무언가가 잘못됐다.
2-3. 샘플링 편향
우리가 처음 fish_data를 만들 때 도미 데이터와 빙어 데이터를 합쳤다. 그런데 섞은게 아니라 그냥 이어붙였다. 따라서 앞에 35개는 도미 데이터, 나머지 14개는 빙어 데이터인 형태로 합쳐진 것이다. 우리는 앞에 35개는 훈련 세트, 뒤에 14개는 테스트 세트로 썼다. 즉, 도미 데이터만으로 kn 객체가 훈련된 것이다.
모델을 훈련할 때는 훈련 세트와 테스트 세트에 샘플 별 클래스가 골고루 섞여 있어야 한다. 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우치게 되어 샘플링 편향이라는 문제가 발생된다. 한 쪽 클래스에 집중되어 모델이 훈련된다는 의미이다! 따라서 훈련 세트와 테스트 세트를 나누기 전, 데이터를 섞든지, 아니면 골고루 샘플을 뽑아서 훈련 세트와 테스트 세트를 만들던지 해야한다.
2-4. 넘파이
넘파이는 파이썬의 대표적인 배열 라이브러리이다. 파이썬 리스트로 3차원 이상의 리스트를 표현하기는 좀 번거롭다. 넘파이는 고차원 배열을 손쉽게 만들고 조작할 수 있는 도구를 다수 제공한다.
import numpy as np
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)
print(input_arr)
(결과) [[ 25.4 242. ]
[ 26.3 290. ]
...
[ 15. 19.9]]
출력된 내용과 형태가 파이썬 리스트와 비슷하다. 다음과 같이 넘파이 배열 객체는 shape 속성도 제공한다.
print(input_arr.shape)
(결과) (49, 2)
넘파이를 배웠으니, 이제 무작위로 샘플을 선택하는 법을 배워보자. 훈련 세트와 테스트 세트를 나눌 때 주의할 점은, 훈련 세트와 테스트 세트 내 데이터와 타깃의 위치가 동일해야 한다는 것이다. 무작위로 샘플을 선택하여 훈련 세트와 테스트 세트를 나눌 때, 데이터의 두번째 값이 훈련 세트로 갔는데, 라벨의 두번째 값이 테스트 세트로 가면 되겠는가?
넘파이에서 무작위 결과를 만드는 함수들은 실행할 때마다 다른 결과를 만든다. 일정한 결과를 얻으려면 초기에 랜덤 시드를 지정해야 한다. 랜덤 시드를 42로 지정해서 무작위로 샘플 선택하는 코드를 작성해보자.
np.random.seed(42)
index = np.arange(49) # 0 ~ 48까지 1씩 증가하는 배열 생성
np.random.shuffle(index) # index 배열을 무작위로 섞음
print(index)
(결과) [13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33 30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28 38]
넘파이에는 배열 인덱싱이란 기능도 제공한다. 리스트 형태로 여러 개의 인덱스를 입력하여 한 번에 여러 개의 원소를 선택하는 기능이다.
print(input_arr[[1, 3, 5]])
(결과) [[ 26.3 290. ]
[ 29. 363. ]
[ 29.7 450. ]]
이제 무작위로 섞인 index 변수를 이용하여 훈련 세트와 테스트 세트를 만들어보자.
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]
import matplotlib.pyplot as plt
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(test_input[:, 0], test_input[:, 1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
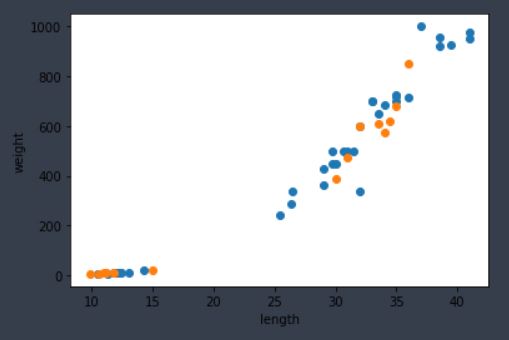
그림 2-1. 코드 결과
그림 2-1을 보면 훈련 세트 안에 도미 데이터와 빙어 데이터가 잘 섞여 있다는 것을 확인할 수 있다.
2-5. 두 번째 머신러닝 프로그램
kn = kn.fit(train_input, train_target)
kn.score(test_input, test_target)
(결과) 1.0
정확도가 100%로 바뀌었다!
예측 결과와 실제 타깃을 비교해보자
kn.predict(test_input))
(결과) array([0 0 1 0 1 1 1 0 1 1 0 1 1 0])
test_target
(결과) array([0 0 1 0 1 1 1 0 1 1 0 1 1 0])
결과가 동일하다는 것을 확인할 수 있다!
참고로 predict 메소드는 array()에 감싸져서 출력 결과가 반환되는데, 이는 넘파이 배열을 의미한다.
Leave a comment