
[Machine learning] 1. 마켓과 머신러닝
본 포스팅은 “혼자 공부하는 머신러닝+딥러닝” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
1-1. 생선 분류 문제
생선을 분류하는 문제이다. 도미를 분류하고 싶은데, 전문가는 생선 길이가 30cm 이상이면 도미라고 알려줬다.
if fish_length >= 30:
print("도미")
위 코드로 도미를 제대로 분류할 수 있을까? 다른 생선도 분명 30cm 이상의 길이를 가진 녀석이 있을 것이다.
우리는 잘 모르니, 머신러닝의 도움을 받아보자.
1-2. 도미 데이터 준비
누군가가 창고에서 생선의 길이와 무게를 재어 다음과 같이 기록하였다. 창고에는 도미와 빙어만 있다고 한다. 누군가가 고생하여 만든 소중한 데이터를 이용하여 도미와 빙어를 분류해보자.
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
위 데이터는 도미 관련 데이터이다.
머신러닝에서 여러 개의 종류 중 하나를 구별해 내는 문제를 분류라고 한다. 우리가 풀려는 문제와 같이, 2개의 클래스 중 하나를 고르는 문제는 이진 분류라고 한다.
위 데이터 처럼 도미의 길이와 무게는 도미의 특징이라고도 할 수 있다. 이러한 특징을 ‘특성’이라고 부른다.
위 데이터를 숫자 그대로 보자니 좀 번잡해 보인다. 한눈에 직관적으로 볼 수 있는 방법이 없을까? 다음과 같이 시각화를 해보자.
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
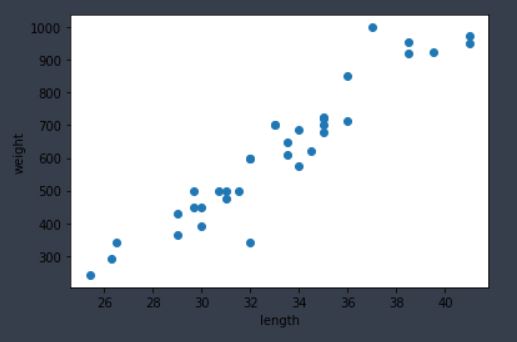
그림 1-1. 코드 결과
그림 1-1 과 같은 그래프를 산점도(Scatter plot)라고 한다. x축은 길이, y축은 무게를 나타낸다. 대체로 산점도 그래프가 일직선에 가까운 형태로 나타나있다. 이러한 경우를 선형적 이라고 말한다.
1-3. 빙어 데이터 준비
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
위 데이터는 빙어 관련 데이터이다.
빙어 데이터를 도미 데이터와 합쳐서 산점도로 나타내보자!
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
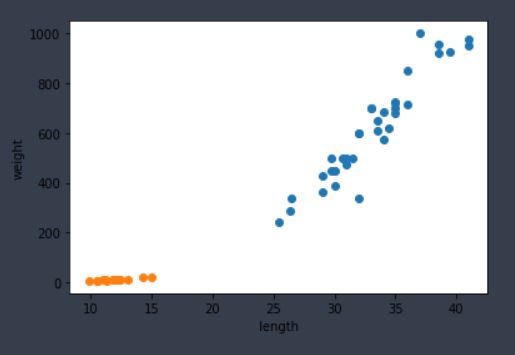
그림 1-2. 코드 결과
빙어의 길이와 무게간 상관관계는 도미와 약간 다르다. 길이와 무게가 생각만큼 비례관계가 아닌것으로 보인다. 또한 빙어와 도미의 산점도가 완전히 구분되어 보이는 것으로 봐서, 두 생선의 길이, 무게는 완전히 다르다는 것을 알 수 있다.
1-4. 첫 번째 머신러닝 프로그램
이제 K-최근접 이웃(K-Nearest Neighbors) 알고리즘으로 도미와 빙어를 구분해 보려 한다. 먼저 도미와 빙어 데이터를 담은 리스트를 더하여 하나의 리스트로 만들어 보자
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
print('length: ', length)
print('weight: ', weight)
(결과) length: [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
weight: [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
이제 사이킷런 패키지를 이용하여 각 특성의 리스트를 세로 방향으로 늘어뜨린 2차원 리스트로 만들어보자!
fish_data = [[l, w] for l, w in zip(length, weight)] # 두 리스트를 zip 함수로 묶으면, 두 리스트의 값들을 짝지어 튜플로 반환함
print('fish data: ', fish_data)
(결과) fish data: [[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0], [29.7, 450.0], [29.7, 500.0], [30.0, 390.0], [30.0, 450.0], [30.7, 500.0], [31.0, 475.0], [31.0, 500.0], [31.5, 500.0], [32.0, 340.0], [32.0, 600.0], [32.0, 600.0], [33.0, 700.0], [33.0, 700.0], [33.5, 610.0], [33.5, 650.0], [34.0, 575.0], [34.0, 685.0], [34.5, 620.0], [35.0, 680.0], [35.0, 700.0], [35.0, 725.0], [35.0, 720.0], [36.0, 714.0], [36.0, 850.0], [37.0, 1000.0], [38.5, 920.0], [38.5, 955.0], [39.5, 925.0], [41.0, 975.0], [41.0, 950.0], [9.8, 6.7], [10.5, 7.5], [10.6, 7.0], [11.0, 9.7], [11.2, 9.8], [11.3, 8.7], [11.8, 10.0], [11.8, 9.9], [12.0, 9.8], [12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
이제 정답 리스트를 만들어보자. 위 fish_data와 짝을 지어 값을 나열하는 정답 리스트를 만들것이다. 컴퓨터는 0과 1만 이해할 수 있으므로 빙어와 도미를 각각 0과 1로 나타낼 것이다.
fish_target = [1] * 35 + [0] * 14 # 도미 35개, 빙어 14개 데이터 있었음
print('fish target: ', fish_target)
(결과) fish target: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
이제 사이킷런 패키지에서 KNeighborsClassifier를 임포트하여, KNeighborsClassifier 클래스의 객체를 만들자.
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
kn = KNeighborsClassifier()
위 kn 객체에 fist_data와 fish_target을 전달하여 도미를 찾기 위한 기준을 학습시킬 것이다! 이러한 과정을 훈련이라고 한다. 사이킷런에서는 fit() 메소드가 훈련시키는 역할을 한다.
kn.fit(fish_data, fish_target)
객체 kn은 얼마나 잘 훈련되었을까? 사이킷런에서 모델을 평가하는 메소드는 score()이다! 이 메소드는 0에서 1 사이의 값을 반환한다. 1은 모든 데이터를 정확히 맞췄다는 의미이며, 0.5는 절반만 맞췄다는 의미이다.
kn.score(fish_data, fish_target)
(결과) 1.0
확인해보니 1.0이 나왔다! 이 값을 정확도라 하는데 정확도가 100% 가 나왔으니 도미와 빙어를 완벽하게 분류했다 말할 수 있겠다!
1-5. K-최근접 이웃 알고리즘
이 알고리즘은 매우 간단하다. 어떤 데이터에 대한 답을 구할 때, 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용한다. 가령, 그림 1-2 산점도의 파란색 근처에 새로운 데이터(길이 30, 무게 600인 생선)가 표시되었다고 가정해보자. 이 데이터의 근처에는 도미 데이터가 많이 있으므로, 모델은 새로운 데이터를 도미로 판단하게 될 것이다.
kn.predict([30, 600])
(결과) array([1])
역시 도미로 판단하였다. predict() 메소드는 새로운 데이터의 정답을 예측한다.
정리하자면, K-최근접 이웃 알고리즘은 새로운 데이터에 대해 예측할 때 가장 가까운 직선거리에 어떤 데이터가 있는지 살펴 가장 많은 데이터에 대한 클래스를 출력으로 반환한다. K-최근접 이웃 알고리즘의 단점은 데이터가 아주 많을 때 사용하기 어렵다는 것이다. 데이터가 많을 수록 메모리가 많이 필요하고 직선거리를 계산하는데도 많은 시간이 필요하기 때문이다.
참고로 위 코드들에 의해 생성된 kn객체는 fish_data와 fish_target을 별도의 변수에 저장한다.
print(kn._fit_X)
print(kn._y)
(결과) fish_data: [[ 25.4 242. ]
[ 26.3 290. ]
...
[ 15. 19.9]]
fish_target: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
K-최근접 이웃 알고리즘은 새로운 데이터를 예측할 때 직선거리에 어떤 데이터가 있는지 살펴 가장 많은 데이터에 대한 클래스를 출력으로 반환한다 하였다. 가장 많은 데이터의 기준은 몇개일까? 이것은 정하기 나름이다! 디폴트 값은 5이지만 n_neighbors 매개변수를 이용하여 바꿀 수 있다!
kn49 = KNeighborsClassifier(n_neighbors=49)
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
(결과) 0.7142857142857143 # 49개 중 35개 맞춤
n_neighbors를 49로 설정했더니, 정확도가 많이 줄었다. 데이터 전체가 49개인데 전체를 살펴보고 가장 많은 데이터의 클래스를 출력했으니, 전부 도미로 출력됐을 것이다.
Leave a comment