
[Deeplearning(Tensorflow)] 9. LSTM과 GRU 셀
본 포스팅은 “혼자 공부하는 머신러닝+딥러닝” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
9-1. LSTM 구조
LSTM(Long Shor-Term Memory)는 단기 기억을 오래 기억하기 위해 고안되었다. LSTM에는 입력과 가중치를 곱하고 절편을 더해 활성화 함수를 통과시키는 구조를 여러개 가지고 있다. 이런 계산 결과는 다음 타임스텝에 재사용 된다.
은닉상태를 먼저 보자. 은닉 상태는 입력과 이전 타임스텝의 은닉 상태를 가중치에 곱한 후 활성화 함수를 통과시켜 다음 은닉 상태를 만든다. 이 때 활성화 함수르 시그모이드 활성화 함수를 사용한다. 또 tanh 활성화 함수를 통과한 어떤 값과 곱해져서 은닉 상태를 만든다. 앞으로 나올 기호 중, 편의상 은닉 상태 계산시 가중치 $w_{x}$ 와 $w_{h}$ 를 통틀어 $w_{o}$ 라고 하자.

그림 9-1. LSTM 구조

그림 9-2. LSTM 수식
LSTM에는 순환되는 상태가 2개다. 은닉 상태 말고 셀 상태(Cell state)라고 부르는 값이 따로 있다. 셀 상태는 다음 층으로 전달되지 않고 LSTM 셀에만 순환되는 값이다. 은닉 상태 h와 구분지어 c로 표시하자. 셀 상태를 계산하는 과정은 다음과 같다.
먼저 입력과 은닉 상태를 또 다른 가중치 $w_{f}$ 에 곱한 다음 시그모이드 함수를 통과시킨다. 그 다음 이전 타임스텝의 셀 상태와 곱하여 새로운 셀 상태를 만든다. 이 셀 상태가 오른쪽 tanh 함수를 통과하여 새로운 은닉 상태를 만드는데 기여한다. 중요한 것은 입력과 은닉 상태에 곱해지는 가중치 $w_{o}$와 $w_{f}$ 가 다르다는 것이다. 이 두 작은 셀은 각기 다른 기능을 위해 훈련된다.
여기에 2개의 작은 셀이 추가되어 셀 상태를 만드는데 기여한다. 이전처럼 입력과 은닉 상태를 각기 다른 가중치에 곱한 다음, 하나는 시그모이드 함수를 통과시키고 다른 하나는 tanh 함수를 통과시킨다. 그 다음 두 결과를 곱한 후 이전 셀 상태와 더한다. 이 결과가 최종적인 다음 셀 상태가 된다.
그림 9-1 처럼 세 군데의 곱셈을 왼쪽부터 차례대로 삭제 게이트, 입력 게이트, 출력 게이트 라고 부른다. 삭제 게이트는 셀 상태에 있는 정보를 제거하는 역할을 하고, 입력 게이트는 새로운 정보를 셀 상태에 추가한다. 출력 게이트를 통해 이 셀 상태가 다음 은닉 상태로 출력된다.
9-2. LSTM 신경망 훈련하기
from tensorflow.keras.datasets import imdb
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = imdb.load_data(num_words=500)
train_input, val_input, train_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)
val_seq = pad_sequences(val_input, maxlen=100)
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.Embedding(500, 16, input_length=100))
model.add(keras.layers.LSTM(8))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
(결과) Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 16) 8000
_________________________________________________________________
lstm (LSTM) (None, 8) 800
_________________________________________________________________
dense (Dense) (None, 1) 9
=================================================================
Total params: 8,809
Trainable params: 8,809
Non-trainable params: 0
_________________________________________________________________
SimpleRNN 클래스의 모델 파라미터 개수는 200개였다. LSTM 셀에는 작은 셀이 4개가 있으므로 정확히 4배가 늘어 모델 파라미터 개수는 800개가 되었다.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-lstm-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model.fit(train_seq, train_target, epochs=100, batch_size=64, validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
(결과) Epoch 1/100
313/313 [==============================] - 16s 52ms/step - loss: 0.6926 - accuracy: 0.5432 - val_loss: 0.6919 - val_accuracy: 0.5836
Epoch 2/100
...
Epoch 42/100
313/313 [==============================] - 15s 49ms/step - loss: 0.3978 - accuracy: 0.8206 - val_loss: 0.4283 - val_accuracy: 0.8026
Epoch 43/100
313/313 [==============================] - 16s 51ms/step - loss: 0.3973 - accuracy: 0.8217 - val_loss: 0.4273 - val_accuracy: 0.8074
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
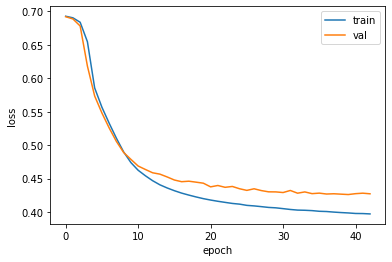
그림 9-3. 코드 결과
9-3. 순환층에 드롭아웃 적용하기
완전 연결 신경망과 합성곱 신경망에서는 Dropout 클래스를 사용하여 드롭아웃을 적용했다. 순환층은 자체적으로 드롭아웃 기능을 제공한다. SimpleRNN과 LSTM 클래스 모두 dropout 매개변수와 recurrent_dropout 매개변수를 갖는다. dropout 매개변수는 셀의 입력에 드롭아웃을 적용한다. recurrent_dropout은 순환되는 은닉 상태에 드롭아웃을 적용한다. 기술적인 문제로 인해 recurrent_dropout을 사용하면 GPU를 사용하여 모델을 훈련하지 못한다. 이 때문에 모델의 훈련 속도가 크게 느려진다. 여기에서는 dropout만 사용해보자.
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500, 16, input_length=100))
model2.add(keras.layers.LSTM(8, dropout=0.3))
model2.add(keras.layerse.Dense(1, activation='sigmoid'))
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-dropout-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=64, validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
(결과) Epoch 1/100
313/313 [==============================] - 18s 57ms/step - loss: 0.6928 - accuracy: 0.5210 - val_loss: 0.6922 - val_accuracy: 0.5452
Epoch 2/100
313/313 [==============================] - 16s 50ms/step - loss: 0.6910 - accuracy: 0.5778 - val_loss: 0.6899 - val_accuracy: 0.6154
...
Epoch 44/100
313/313 [==============================] - 29s 94ms/step - loss: 0.4110 - accuracy: 0.8140 - val_loss: 0.4284 - val_accuracy: 0.8038
Epoch 45/100
313/313 [==============================] - 25s 81ms/step - loss: 0.4107 - accuracy: 0.8110 - val_loss: 0.4288 - val_accuracy: 0.8004
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
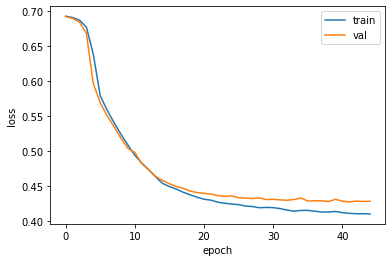
그림 9-4. 코드 결과
드롭아웃의 효과가 발휘된 것으로 보인다. 훈련 손실과 검증 손실 간 차이가 좁혀진 것을 볼 수 있다.
9-4. 2개의 층을 연결하기
순환층 연결시 주의할 점이 있다. 순환층의 은닉 상태는 샘플의 마지막 타임스텝에 대한 은닉 상태만 다음 층으로 전달된다. 하지만 순환층을 쌓게 되면 모든 순환층에 순차 데이터가 필요하다. 따라서 앞쪽의 순환층이 모든 타임스텝에 대한 은닉 상태를 출력해야 한다. 오직 마지막 순환층만 마지막 타임스텝의 은닉 상태를 출력해야 한다. 케라스의 순환층에서 모든 타임스텝의 은닉 상태를 출력하려면 마지막을 제외한 다른 모든 순환층에서 return_sequences 매개변수를 True로 지정하면 된다.
model3 = keras.Sequential()
model3.add(keras.layers.Embedding(500, 16, input_length=100))
model3.add(keras.layers.LSTM(8, dropout=0.3, return_sequences=True))
model3.add(keras.layers.LSTM(8, dropout=0.3))
model3.add(keras.layers.Dense(1, activation='sigmoid'))
model3.summary()
(결과) Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_4 (Embedding) (None, 100, 16) 8000
_________________________________________________________________
lstm_3 (LSTM) (None, 100, 8) 800
_________________________________________________________________
lstm_4 (LSTM) (None, 8) 544
_________________________________________________________________
dense_2 (Dense) (None, 1) 9
=================================================================
Total params: 9,353
Trainable params: 9,353
Non-trainable params: 0
_________________________________________________________________
모델 파라미터 개수는 각각 500 x 16 = 8000, (16 x 8 + 8 x 8 + 8) x 4 = 800, (8 x 8 + 8 x 8 + 8) x 4 = 544, 8 x 1 + 1 = 9 로 산출된다. 첫 번째 LSTM 층을 보면 모든 타임스텝 100개의 은닉 상태를 출력하므로 출력 크기가 (None, 100, 8)로 표시되었다. 그러나 두 번째 LSTM층은 마지막 타임스텝의 은닉 상태만 출력하므로 (None, 8) 이다.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model3.compile(optimizer=rmsprop, loss='binary_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-2rnn-model.h5')
earlystopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model3.fit(train_seq, train_target, epochs=100, batch_size=64, validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, earlystopping_cb])
(결과) Epoch 1/100
313/313 [==============================] - 40s 127ms/step - loss: 0.6921 - accuracy: 0.5325 - val_loss: 0.6910 - val_accuracy: 0.5930
Epoch 2/100
313/313 [==============================] - 37s 120ms/step - loss: 0.6863 - accuracy: 0.6000 - val_loss: 0.6787 - val_accuracy: 0.6614
...
Epoch 38/100
313/313 [==============================] - 37s 119ms/step - loss: 0.4212 - accuracy: 0.8061 - val_loss: 0.4350 - val_accuracy: 0.7972
Epoch 39/100
313/313 [==============================] - 37s 117ms/step - loss: 0.4212 - accuracy: 0.8065 - val_loss: 0.4375 - val_accuracy: 0.7954
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
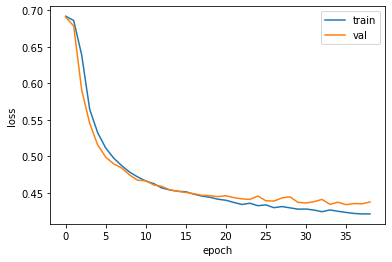
그림 9-5. 코드 결과
과대적합을 제어하면서 손실을 최대한 낮췄다.
9-5. GRU 구조
GRU(Gated Recurrent Unit)은 LSTM을 간소화한 버전으로 생각할 수 있다. 이 셀은 LSTM 처럼 셀 상태를 계산하지 않고 은닉 상태 하나만 포함한다.
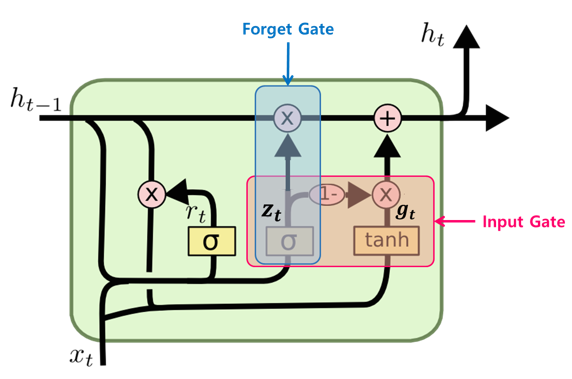
그림 9-6. GRU 구조

그림 9-7. GRU 수식
GRU 셀에는 은닉 상태와 입력에 가중치를 곱하고 절편을 더하는 작은 셀이 3개 들어 있다. 2개는 시그모이드 활성화 함수를 사용하고, 하나는 tanh 활성화 함수를 사용한다. 여기에서도 은닉 상태와 입력에 곱해지는 가중치를 합쳐서 나타냈다. 맨 왼쪽 $w_{z}$ 를 사용하는 셀의 출력이 은닉 상태에 바로 곱해져 삭제 게이트 역할을 수행한다. 이와 똑같은 출력을 1에서 뺀 다음 가장 오른쪽 $w_{g}$를 사용하는 셀의 출력에 곱한다. 이는 입력되는 정보를 제어하는 역할을 수행한다. $w_{r}$을 사용하는 셀에서 출력된 값은 $w_{g}$ 셀이 사용할 은닉 상태의 정보를 제어한다. GRU 셀은 LSTM 보다 가중치가 적기 때문에 계산량이 적지만 LSTM 못지않는 좋은 성능을 내는 것으로 알려졌다.
9-6. GRU 신경망 훈련하기
model4 = keras.Sequential()
model4.add(keras.layers.Embedding(500, 16, input_length=100))
model4.add(keras.layers.GRU(8))
model4.add(keras.layers.Dense(1, activation='sigmoid'))
model4.summary()
(결과) Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_5 (Embedding) (None, 100, 16) 8000
_________________________________________________________________
gru (GRU) (None, 8) 624
_________________________________________________________________
dense_3 (Dense) (None, 1) 9
=================================================================
Total params: 8,633
Trainable params: 8,633
Non-trainable params: 0
_________________________________________________________________
GRU 층의 모델 파라미터 개수를 계산해보자. GRU 셀에는 3개의 작은 셀이 있으므로 (16 x 8 + 8 x 8 + 8) x 3 = 600개가 있다. 여기에 한가지가 더 있다. 사실 $w_{g}$ 로 표현된게 $w_{x}$ 와 $w_{h}$ 로 나눠진다. 이렇게 나누어 계산하면 $h_{t-1}$에 곱해지는 절편이 별도로 필요하다. 곱해지는 항마다 하나씩 절편이 추가되는데 뉴런이 8개 있으므로 총 24개의 모델 파라미터가 더해진다. 텐서플로가 이런 계산 방식을 사용하는 이유는 GPU를 잘 활용하기 위해서이다. 널리 통용되는 이론과 구현이 종종 차이가 날 수 있으니 GRU 층의 모델 파라미터 개수를 혼동하지 말자!
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model4.compile(optimizer=rmsprop, loss='binary_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-gru-model.h5')
earlystopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model4.fit(train_seq, train_target, epochs=100, batch_size=64, validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
(결과) Epoch 1/100
313/313 [==============================] - 26s 84ms/step - loss: 0.6921 - accuracy: 0.5469 - val_loss: 0.6912 - val_accuracy: 0.5688
Epoch 2/100
313/313 [==============================] - 27s 85ms/step - loss: 0.6900 - accuracy: 0.5736 - val_loss: 0.6889 - val_accuracy: 0.5796
...
Epoch 34/100
313/313 [==============================] - 21s 68ms/step - loss: 0.4184 - accuracy: 0.8142 - val_loss: 0.4478 - val_accuracy: 0.7958
Epoch 35/100
313/313 [==============================] - 22s 69ms/step - loss: 0.4177 - accuracy: 0.8141 - val_loss: 0.4511 - val_accuracy: 0.7884
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
그림 9-8. 코드 결과
드롭아웃을 사용하지 않아 이전보다 훈련 손실과 검증 손실 사이에 차이가 있지만 훈련 과정이 잘 수렴되고 있는 것을 확인할 수 있다.
Leave a comment