
[Deeplearning(Tensorflow)] 5. 합성곱 신경망을 사용한 이미지 분류
본 포스팅은 “혼자 공부하는 머신러닝+딥러닝” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
5-1. 패션 MNIST 데이터 불러오기
3장에서 완전 연결 신경망에 입력 이미지를 밀집층에 연결하기 위해 일렬로 펼쳤다. 합성곱 신경망은 2차원 이미지를 그대로 사용하므로 일렬로 펼칠 필요가 없다. 다만 입력 이미지는 항상 깊이 차원이 있어야 한다. reshape() 메소드로 전체 배열 차원을 그대로 유지하면서 마지막에 차원을 간단히 추가하자.
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input.reshape(-1, 28, 28, 1) / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
(48000, 28, 28) 크기가 (48000, 28 ,28, 1) 크기가 됐다.
5-2. 합성곱 신경망 만들기
합성곱 신경망 구조는 합성곱 층으로 이미지에서 특징을 감지한 후 밀집층으로 클래스에 따른 분류 확률을 계산한다.
model = keras.Sequential()
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu', padding='same', input_shape=(28, 28, 1)))
model.add(keras.layers.MaxPooling2D(2))
합성곱 층에서 32개 필터를 사용하여 특성 맵의 깊이는 32가 된다. (2, 2) 최대 풀링을 적용하여 특성 맵의 크기는 절반으로 줄어든다. 두 번째 합성곱-풀링 층도 추가해보자.
model.add(keras.layers.Conv2D(64, kernel_size=3, activation='relu', padding='same')
model.add(keras.layers.MaxPooling2D(2))
64개의 필터를 사용하여 최종적으로 만들어지는 특성 맵의 크기는 (7, 7, 64)가 된다.
이제 3차원 특성 맵을 일렬로 펼치고 완전 연결 신경망을 만들자.
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation='softmax'))
은닉층과 출력층 사이에 드롭아웃을 넣었다. 드롭아웃 층이 은닉층의 과대적합을 막아 성능을 조금 더 개선해 줄 것이다. 패션 MNIST 데이터셋은 클래스 10개를 분류하는 다중 분류 문제이다. 마지막 층의 활성화 함수는 소프트맥스를 사용한다. 이제 summary() 메소드로 모델 구조를 출력해보자.
model.summary()
(결과) Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 3136) 0
_________________________________________________________________
dense_2 (Dense) (None, 100) 313700
_________________________________________________________________
dropout_1 (Dropout) (None, 100) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 1010
=================================================================
Total params: 333,526
Trainable params: 333,526
Non-trainable params: 0
_________________________________________________________________
첫번째 파라미터 개수는 3x3x32+32=320 식에 의해 산출된다. 두번째 파라미터 개수는 3x3x32x64+64=18496 식에 의해 나온다. 세번째 파라미터 개수는 3136x100+100=313700 식으로 나오며 마지막 파라미터 개수는 100x10+10 식에 의해 나온다. 필터마다 하나의 절편이 있다는 것을 꼭 기억하자!
케라스는 summary() 메소드 외에도 층의 구성을 그림으로 표현해주는 plot_model() 함수를 제공한다.
keras.utils.plot_model(model)

그림 5-1. 코드 결과
plot_model() 함수의 show_shapes 매개변수를 True로 설정하면 그림에 입력과 출력의 크기를 표시해준다. 또한 to_file 매개변수에 파일 이름을 지정하면 출력한 이미지를 파일로 저장한다. dpi 매개변수로 해상도도 지정할 수 있다.
keras.utils.plot_model(model, show_shapes=True, to_file='cnn-architecture.png', dpi=300)

그림 5-2. 코드 결과
5-3. 모델 컴파일과 훈련
케라스 API의 장점은 딥러닝 모델의 종류나 구성 방식에 상관없이 컴파일과 훈련 과정이 같다는 것이다. Adam 옵티마이저를 사용하고 ModelCheckpoint 콜백과 EarlyStoppig 콜백을 함께 사용해 조기 종료 기법을 구현하자.
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('beset-cnn-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
(결과) Epoch 1/20
1500/1500 [==============================] - 37s 24ms/step - loss: 0.5345 - accuracy: 0.8059 - val_loss: 0.3720 - val_accuracy: 0.8556
Epoch 2/20
1500/1500 [==============================] - 37s 24ms/step - loss: 0.3575 - accuracy: 0.8724 - val_loss: 0.2879 - val_accuracy: 0.8920
Epoch 3/20
1500/1500 [==============================] - 37s 25ms/step - loss: 0.3047 - accuracy: 0.8894 - val_loss: 0.2647 - val_accuracy: 0.9031
Epoch 4/20
1500/1500 [==============================] - 37s 25ms/step - loss: 0.2702 - accuracy: 0.9015 - val_loss: 0.2447 - val_accuracy: 0.9086
Epoch 5/20
1500/1500 [==============================] - 39s 26ms/step - loss: 0.2453 - accuracy: 0.9101 - val_loss: 0.2362 - val_accuracy: 0.9103
Epoch 6/20
1500/1500 [==============================] - 38s 25ms/step - loss: 0.2275 - accuracy: 0.9165 - val_loss: 0.2226 - val_accuracy: 0.9137
Epoch 7/20
1500/1500 [==============================] - 37s 25ms/step - loss: 0.2059 - accuracy: 0.9249 - val_loss: 0.2210 - val_accuracy: 0.9186
Epoch 8/20
1500/1500 [==============================] - 37s 25ms/step - loss: 0.1943 - accuracy: 0.9295 - val_loss: 0.2262 - val_accuracy: 0.9180
Epoch 9/20
1500/1500 [==============================] - 39s 26ms/step - loss: 0.1780 - accuracy: 0.9340 - val_loss: 0.2355 - val_accuracy: 0.9144
조기 종료가 잘 이루어졌는지 확인해보자.
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
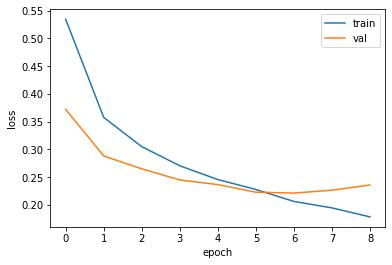
그림 5-3. 코드 결과
검증 세트에 대한 손실이 점차 감소하다가 정체되기 시작하고 훈련 세트에 대한 손실은 점점 더 낮아지고 있다. EarlyStopping 클래스에서 resotre_best_weights=True로 저장했으므로 현재 model 객체가 최적의 모델 파라미터로 복원되어 있다. 즉 ModelCheckpoint 콜백이 저장한 best-cnn-model.h5 파일을 다시 읽을 필요가 없다. 이제 세트에 대한 성능을 확인해보자.
model.evaluate(val_scaled, val_target)
(결과) 375/375 [==============================] - 3s 8ms/step - loss: 0.2210 - accuracy: 0.9186
[0.2210034728050232, 0.918583333492279]
EarlyStopping 콜백이 model 객체를 최상의 모델 파라미터로 잘 복원한 것으로 보인다. 3차원 배열을 2차원 형태로 바꾸어 이미지를 출력해보자.
plt.imshow(val_scaled[0].reshape(28, 28), cmap='gray_r')
plt.show()

그림 5-4. 코드 결과
핸드백 이미지로 보인다. predict() 에서 10개의 클래스에 대한 예측 확률을 출력하자.
preds = model.predict(val_scaled[0:1])
print(preds)
(결과) [[1.2923547e-15 2.0240659e-23 2.0993377e-17 2.7453213e-17 1.8608113e-17 2.1668218e-16 5.5988666e-16 1.1345319e-16 1.0000000e+00 9.9846664e-18]]
참고로 슬라이싱 연산을 사용한 이유는 (28, 28, 1) 이 아닌 (1, 28, 28, 1) 크기를 만들기 위함이다. fit(), predict(), evaluate() 메소드는 모두 입력의 첫 번째 차원이 배치 차원일 것으로 기대한다. 막대 그래프로 각 확률이 몇인지 확인해보자.
plt.bar(range(1, 11), preds[0])
plt.xlabel('class')
plt.show()

그림 5-5. 코드 결과
각 레이블을 리스트로 저장하고 preds 배열에서 가장 큰 인덱스를 찾아 classes 리스트의 인덱스로 사용해보자.
classes = ['티셔츠', '바지', '스웨터', '드레스', '코트', '샌달', '셔츠', '스니커즈', '가방', '앵클 부츠']
import numpy as np
print(classes[np.argmax(preds)])
(결과) 가방
가방으로 잘 예측하였다. 테스트 셋에 대해서도 픽셀값의 범위를 0~1 사이로 바꾸고 이미지를 (28, 28)에서 (28, 28, 1)로 바꾸고 evaluate() 메소드로 테스트 세트에 대한 성능을 측정해보자.
test_scaled=test_input.reshape(-1, 28, 28, 1) / 255.0
model.evaluate(test_scaled, test_target)
(결과) 313/313 [==============================] - 3s 8ms/step - loss: 0.2503 - accuracy: 0.9105
[0.2503235638141632, 0.9104999899864197]
약 91%의 성능이 나왔다!
Leave a comment