
[Deeplearning(pytorch)] 9. 오토인코더 기초와 오토인코더 기반 이미지 특징 추출
본 포스팅은 “펭귄브로의 3분 딥러닝, 파이토치맛” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
9-1. 오토인코더 기초
데이터 형태와 관계없이 사람이 레이블링 하여 정답을 직접 알려주면 머신러닝 모델은 효율적으로 학습할 수 있다. 하지만 데이터셋에 정답이 포함되지 않으면 이야기가 달라진다. 정답 없이 주어진 데이터만으로 패턴을 찾는 것을 비지도학습이라 한다. 지도학습은 입력 x와 정답 y 사이를 잇는 관계를 찾는 것이다. 오차를 측정하여 현재 예측값이 얼마나 틀렸는지 확인하고 이를 기반으로 정정할 수 있다. 비지도학습은 오차값을 구하기가 모호하다.
오토인코더는 ‘정답이 있으면 오차값을 구할 수 있다!’ 라는 아이디어를 빌려 입력 x를 받으면 입력 x를 예측하여, 신경망에 의미 있는 정보가 쌓이도록 설계된 신경망이다. 즉 오토인코더에서는 입력도 x 정답도 x 인 것이다. 신경망은 범용근사자(Universal function approximator)로서 근사치를 출력하므로 x와 완전히 같은 출력을 낼 수 없다. 입력된 x를 복원한다는 개념이 더 맞다! 그러므로 오차값에 x를 얼마나 복원했는지를 의미하는 복원 오차, 또는 정보손실값(Reconstruction loss)라는 용어를 사용한다!
오토인코더의 또 다른 특징은 입력과 출력의 크기가 같지만, 중간으로 갈수록 신경망의 차원이 줄어든다는 것이다. 정보의 통로가 줄어들고 병목현상이 일어나 입력의 특징들이 압축되도록 학습한다. 작은 차원에 고인 압축된 표현을 잠재 변수(Latent variable) 라 하고, 간단히 z라고도 부른다. 잠재 변수의 앞뒤를 구분하여, 앞부분은 인코더(Encoder) 뒷부분은 디코더(Decoder) 라고 한다. 인코더는 정보를 받아 압축하며, 디코더는 압축된 표현을 풀어 입력을 복원하는 역할을 한다.
오토인코더가 입력으로 받은 이미지를 복원하도록 학습하면 잠재 변수에 이미지의 정보가 저장된다. 낮은 차원에 높은 밀도로 표현된 데이터로써, 의미의 압축이 잠재 변수에서 일어난다. 의미의 압축은 복잡한 데이터의 의미를 담는 것이라 볼 수 있다. 정보를 압축할 수 있다는 것은 정보를 구성하는데 우선순위가 있다는 뜻이 된다. 인물 사진에서 배경색이 중요한 요소가 아니라는 점은 의미 압축의 한가지 예라 할 수 있다. 즉, 압축은 정보에서 덜 중요한 요소를 버리는 과정이라 정의할 수 있다.
오토인코더는 반드시 정보의 손실을 가져온다. 정보의 손실이 원본 데이터의 디테일을 잃어버린다고 볼 수 있지만, 중요한 정보만 남겨두는 일종의 데이터 가공이라 볼 수도 있다. 이런 특징으로 오토인코더는 복잡한 비선형 데이터의 차원을 줄이는 용도로 쓰일 수 있다. 또한, 비정상 거래 검출, 데이터 시각화와 복원, 의미 추출, 이미지 검색 등에도 쓰이며, 기계 번역과 생성 모델 등 여러 가지 파생 모델에 응용되고 있다.
9-2. 오토인코더로 이미지 특징 추출하기
Fashion MNIST 데이터셋을 이용하여 오토인코더 모델을 구현하고 학습해보자.
import torch
import torchvision
import torch.nn.functional as F
from torch import nn, optim
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 3차원 플롯 그리는 용도
from matplotlib import cm # 데이터 포인트에 색상 입히는 용도
import numpy as np
# 하이퍼파라미터 준비
EPOCH = 10
BATCH_SIZE = 64
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
print("Using Device: ", DEVICE)
# Fashion MNIST 데이터셋 로딩
trainset = datasets.FashionMNIST(
root = './.data/',
train = True,
download = True,
transform = transforms.ToTensor()
)
train_loader = torch.utils.data.DataLoader(
dataset = trainset,
batch_size = BATCH_SIZE,
shuffle = True,
num_workers = 2 # 데이터 로딩하는데 서브프로세스 몇 개 사용할 것인가?
)
# 오토인코더 모듈 정의
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# 인코더
self.encoder = nn.Sequential( # 여러 모듈을 하나의 모듈로 묶는 역할! 데이터가 각 레이어를 순차적으로 지나감
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
nn.Linear(12, 3),
)
# 디코더
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28*28),
nn.Sigmoid(),
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
# 모듈, 최적화 함수, 손실 함수 객체 불러옴
autoencoder = Autoencoder().to(DEVICE)
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=0.005)
criterion = nn.MSELoss()
# 한 이폭 완료시 복원이 어떻게 되는지 확인 가능하도록 학습 데이터셋의 5개 이미지 가져와 모델에 바로 넣을 수 있도록 간단한 전처리 수행
view_data = trainset.data[:5].view(-1, 28*28)
view_data = view_data.type(torch.FloatTensor)/255
# 학습하는 함수
def train(autoencoder, train_loader):
autoencoder.train()
for step, (x, label) in enumerate(train_loader):
x = x.view(-1, 28*28).to(DEVICE)
y = x.view(-1, 28*28).to(DEVICE)
label = label.to(DEVICE)
encoded, decoded = autoencoder(x)
loss = criterion(decoded, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 에포크 단위 훈련 및 테스트 데이터(5개) 확인
for epoch in range(1, EPOCH+1):
train(autoencoder, train_loader)
test_x = view_data.to(DEVICE)
_, decoded_data = autoencoder(test_x)
f, a = plt.subplots(2, 5, figsize=(5, 2))
print("[Epoch {}]".format(epoch))
# 원본 테스트 데이터 플롯
for i in range(5):
img = np.reshape(view_data.data.numpy()[i], (28, 28))
a[0][i].imshow(img, cmap='gray') # Fashion MNIST와 같이 회색조 색상 사용
# 복원된 테스트 데이터 플롯
for i in range(5):
img = np.reshape(decoded_data.to("cpu").data.numpy()[i], (28, 28)) # 모델 출력값이 GPU에 아직 남아있으므로 일반 메모리로 가져온 후 넘파이 행렬로 변환
a[1][i].imshow(img, cmap='gray')
plt.show()
(결과) Using Device: cpu
[Epoch 1]

[Epoch 2]

[Epoch 3]

[Epoch 4]

[Epoch 5]

[Epoch 6]

[Epoch 7]

[Epoch 8]

[Epoch 9]

[Epoch 10]

9-3. 잠재 변수 들여다보기
이번에는 학습이 완료된 오토인코더에서 나온 잠재 변수들이 3차원에서 어떻게 분포되는지 살펴보자.
# 원본 이미지 데이터 200개 준비 및 전처리 수행
view_data = trainset.data[:200].view(-1, 28*28)
view_data = view_data.type(torch.FloatTensor)/255.
test_x = view_data.to(DEVICE)
encoded_data, _ = autoencoder(test_x)
encoded_data = encoded_data.to('cpu')
# 딕셔너리형 레이블 준비
CLASSES = {
0: 'T-shirt/top',
1: 'Trouser',
2: 'Pullover',
3: 'Dress',
4: 'Coat',
5: 'Sandal',
6: 'Shirt',
7: 'Sneaker',
8: 'Bag',
9: 'Ankle boot'
}
# Axes3D() 함수로 3차원 액자 만들고 준비한 데이터 넘파이 행렬로 변환
fig = plt.figure(figsize=(10, 8))
ax = Axes3D(fig)
X = encoded_data.data[:,0].numpy()
Y = encoded_data.data[:,1].numpy()
Z = encoded_data.data[:,2].numpy()
labels = trainset.targets[:200].numpy()
# 시각화 수행
for x, y, z, s in zip(X, Y, Z, labels): # zip 함수는 같은 길이의 행렬들을 모아 순서대로 묶어줌
name = CLASSES[s]
color = cm.rainbow(int(255*s/9))
ax.text(x, y, z, name, backgroundcolor=color)
# 3차원에서 축마다 표현될 최소 범위 ~ 최대 범취 지정
ax.set_xlim(X.min(), X.max())
ax.set_ylim(Y.min(), Y.max())
ax.set_zlim(Z.min(), Z.max())
plt.show()
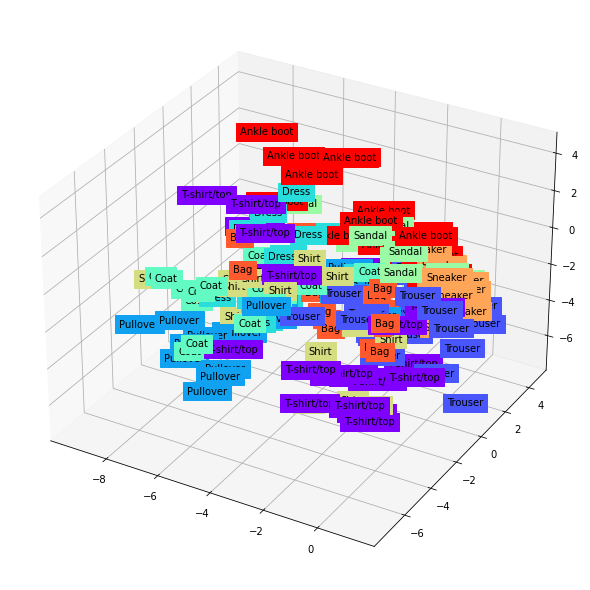
그림 9-11. 코드 결과
Leave a comment