
[Deeplearning(pytorch)] 8. ResNet으로 컬러 데이터셋에 적용하기
본 포스팅은 “펭귄브로의 3분 딥러닝, 파이토치맛” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
8-1. ResNet 소개
ResNet(Residual Network) 모델은 CNN을 응용한 모델이다. 이미지 천만 장을 학습하여 15만 장으로 인식률을 겨루는 이미지넷 대회에서 2015년도 우승한 모델. 신경망을 깊게 쌓으면 오히려 성능이 나빠지는 문제를 해결하는 방법으로 제시했다. 컨벌루션층의 출력에 전의 전 계층에 쓰였던 입력을 더하여 특징이 유실되지 않도록 하였다(그림 8-1).
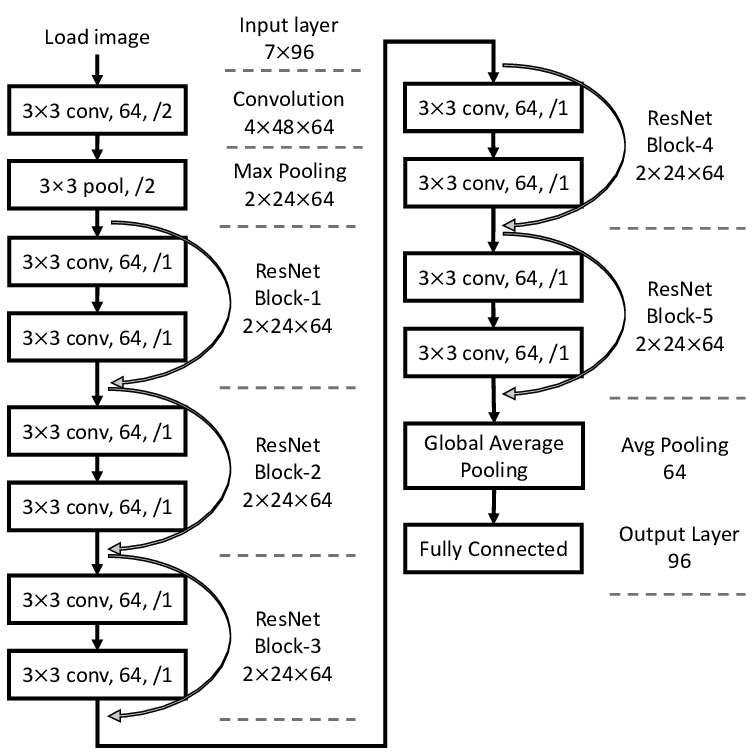
그림 8-1. 코드 결과
8-2. CIFAR-10 데이터셋
CIFAR-10 데이터셋을 사용하겠다. 이미지넷 데이터셋은 매우 방대하고 라이선스 문제도 있어 토치비전에 기본 수록돼있지 않아 직접 받아야 한다. CIFAR-10 데이터셋은 32 x 32 크기의 이미지 6만개를 포함하고 있고, 자동차, 새, 고양이, 사슴 등 10가지 분류가 존재한다. CIFAR-10 데이터셋은 컬러 이미지들을 포함하고 있는데, 컬러 이미지 픽셀값은 몇 가지 채널들로 구성된다. 채널은 이미지의 색상 구성요소를 가리킨다. 빨강, 초록, 파랑 세 종류의 광원을 혼합하여 모든 색을 표현한다. 오늘날 가장 널리 쓰이는 24비트 컬러 이미지는 R, G, B 각각에 8비트씩 색상값을 가지는 3가지 채널을 사용한다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import transforms, datasets, models
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
EPOCHS = 300
BATCH_SIZE - 128
train_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('./.data',
train=True,
download=True,
transform=transforms.Compose([
transforms.RandomCrop(32, padding=1),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5))])),
batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('./.data',
train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5))]))
batch_size=BATCH_SIZE, shuffle=True)
8-3. CNN을 깊게 쌓는 방법
인공 신경망을 여러 개 겹친다고 학습 성능이 좋아지진 않는다. 여러 단계 신경망을 거치며 최초 입력 이미지에 대한 정보가 소실되기 때문이다.
ResNet의 핵심은 네트워크를 작은 블록인 Residual 블록으로 나누었다는 것이다.
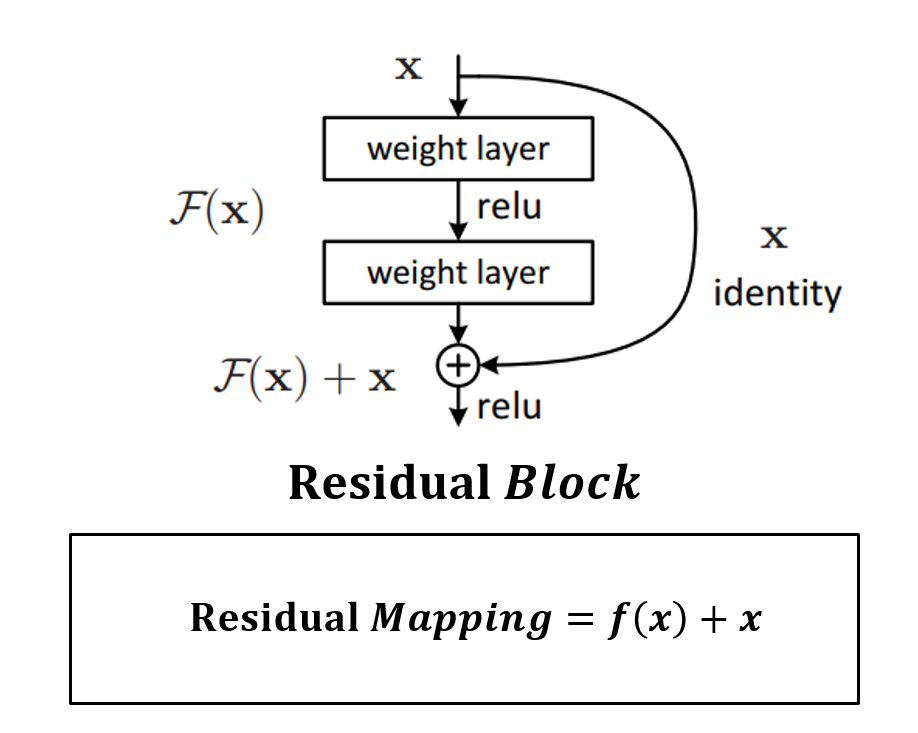
그림 8-2. 코드 결과
Rasidual 블록의 출력에 입력이었던 x를 더하여 모델을 훨씬 깊게 설계할 수 있도록 한다. 즉, 입력과 출력의 관계를 바로 학습하는 것보다, 입력과 출력의 차이를 따로 학습하는게 성능이 좋다는 것이다.
신경망을 깊게 할수록 좋은 이유는 문제를 더 작은 단위로 분해하여 학습 효율이 좋아지기 때문이다. 그러나 계층이 깊어짐에 따라 신호의 강도가 감소하게 된다. ResNet은 입력 데이터를 몇 계층씩 건너뛰어 출력에 더함으로써 이 현상을 완화해준다.
Residual 블록을 BasicBlock 이라는 새로운 파이토치 모듈로 정의해서 사용해보자. 참고로 BasicBlock 코드에는 nn.BatchNorm2d라는 녀석이 있다. 배치 정규화(Batch Normalization)을 수행하는 계층인데, 학습 중 각 계층에 들어가는 입력을 평균과 분산으로 정규화하여, 학습률을 높게 잡을 때 기울기가 소실되거나 발산되는 증상을 예방시켜주는 방법이다. 자체적으로 정규화를 수행해 드롭아웃과 같은 효과를 낸다. 차이라면 드롭아웃은 일부 데이터를 배제하는 반면, 배치 정규화는 신경망 내부 데이터에 직접 영향을 준다.
class BasicBlock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential() # 여러 nn.Module을 하나의 모듈로 묶는 역할. 각 레이어를 데이터가 순차적으로 지나갈 때 사용하면 코드 간결하게 만들 수 있음.
if stride != 1 or in_planes != planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, bias=False), # 증폭하는 역할!
nn.BatchNorm2d(planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) # 이전 입력을 중간층에 더해주어 이미지 맥락 보존되도록 함!
out = F.relu(out)
return out
이제 모델을 정의해보자. 이미지를 받아 컨볼루션과 배치정규화 층을 거친 후, 여러 BasicBlock 층을 통과하고 평균 풀링과 신경망을 거쳐 예측을 출력하도록 하자.
BasicBlock 클래스는 self._make_layer() 함수를 통해 하나의 모듈로 객체화하여 ResNet 모델의 주요 층을 이루도록 할 것이다.
class ResNet(nn.Module):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 16
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False) # RGB 채널 3개를 16개로 만듬
self.bn1 = nn.BatchNorm2d(16)
self.layer1 = self._make_layer(16, 2, stride=1) # 32 x 32 x 16
self.layer2 = self._make_layer(32, 2, stride=2) # 32 x 16 x 16
self.layer3 = self._make_layer(64, 2, stride=2) # 64 x 8 x 8
self.linear = nn.Linear(64, num_classes) # 원소의 개수 64개로 만든 후, 64개 입력 받아 레이블 마다 예측값 내게됨
def _make_layer(self, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers=[]
for stride in strides: # 2번 들어감!
layers.append(BasicBlock(self.in_planes, planes, stride))
self.in_planes = planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, 8)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
정의된 모델 구조는 다음 그림과 같다.

그림 8-3. 정의된 모델 구조
모델을 정의했다면 사용법은 같다. 여기에서는 학습률 감소 기법을 사용한다. 학습률 감소는 학습이 진행하면서 최적화 함수의 학습률을 점점 낮춰서 더 정교하게 최적화한다. 파이토치 내부의 optim.lr_scheduler.StepLR도구를 사용하여 적용가능하다! Scheduler는 에폭마다 호출되고, step_size를 50으로 지정하여, 50번 호출될 때 학습률에 0.1(gamma값)을 곱한다. 즉, 0.1로 시작한 학습률은 50 에폭 이후 0.01로 낮아진다.
model = ResNet().to(DEVICE)
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=0.0005)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1)
def train(model, train_loader, optimzer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuracy
for epoch in range(1, EPOCHS+1):
scheduler.step()
train(model, train_loader, optimizer, epoch)
test_loss, test_accuracy = evaluate(model, test_loader)
print('[{}] Test Loss: {:.4f}, Accuracy: {:.2f}%'.format(epoch, test_loss, test_accuracy))
Leave a comment