
[Deeplearning(pytorch)] 16. 주어진 환경과 상호작용하여 학습하는 DQN
본 포스팅은 “펭귄브로의 3분 딥러닝, 파이토치맛” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
16-1. 강화학습과 DQN 기초
강화학습(Reinforcement learning)은 주어진 환경과 상호작용하여 좋은 점수를 얻는 방향으로 성장하는 머신러닝 분야이다. 그동안 배운 학습법들은 원하는 데이터셋을 외우는 주입식 학습법이었다. 강화학습은 자기주도적 학습법이라 할 수 있다. 강화학습 모델은 주어진 환경에서 시행착오를 겪으며 좋은 피드백을 받는 쪽으로 최적화하며 성장한다.
강화학습은 크게 상태(State), 에이전트(Agent), 행동(Action), 보상(Reward) 4가지 요소로 나눌 수 있다.
1) 에이전트: 인공지능 플레이어
2) 환경: 에이전트가 솔루션을 찾기 위한 무대
3) 행동: 에이전트가 환경 안에서 시행하는 상호작용
4) 보상: 에이전트의 행동에 따른 점수 혹은 결과
2013년 딥마인드는 DQN(Deep q-network) 알고리즘으로 아타리사의 유명 게임들에서 사람보다 월등히 높은 점수를 얻었다.

그림 16-1. DQN 학습 구조
16-2 카드 게임 마스터 하기
카드폴이라는 환경을 구축하여 강화학습을 해보자. 카드폴 게임에서는 막대기를 세우고 오래 버틸수록 점수가 올라간다. 막대기가 오른쪽으로 기울 때는 중심을 다시 맞춰야 하므로 오른쪽 버튼을 눌러 검은색 상자를 오른쪽으로 움직이는 것이 왼쪽 버튼을 눌러 검은색 상자를 왼쪽으로 옮기는 것보다 보상이 클 것으로 예측할 수 있다.
DQN의 주요 특징은 기억하기(Memorize)와 다시보기(Replay)이다.
# 관련 모듈 임포트
import gym # 카드폴 등의 여러 게임 환경 제공하는 패키지
import random
import math
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from collections import deque # 큐(FIFO) 자료구조의 일종. 덱(Double-end queue)은 양쪽 끝에서 삽입과 삭제가 모두 가능한 자료구조
import matplotlib.pyplot as plt
그 다음 하이퍼파라미터를 설정한다. EPS_START와 EPS_END는 엡실론이다. 엡실론이 50%이면 절반의 확률로 무작위 행동을 하고, 나머지 절반의 확률로 학습된 방향으로 행동한다. 무작위로 행동하는 이유는 에이전트가 가능한 모든 행동을 경험하도록 하기 위해서이다. 시작값은 90%이지만 학습이 진행되면서 조금씩 감소해서 5%까지 내려가게하자.
감마는 에이전트가 현재 보상을 미래 보상보다 얼마나 가치 있게 여기는지에 대한 값이다. 1년 뒤 받을 만원과 지금 받는 만원의 가치는 다르므로, 1년뒤 받을 만원은 이자율 만큼 할인해줘야한다. 감마는 이 할인율과 비슷한 개념이다.
# 하이퍼파라미터
EPISODES = 50 # 에피소드 반복 횟수(총 플레이할 게임 수)
EPS_START = 0.9 # 학습 시작 시 에이전트가 무작위로 행동할 확률
EPS_END = 0.05 # 학습 막바지에 에이전트가 무작위로 행동할 확률
EPS_DECAY = 200 # 학습 진행 시 에이전트가 무작위로 행동할 확률을 EPS_START에서 EPS_END 까지 점진적으로 감소시키는 값
GAMMA = 0.8 # 할인계수
LR = 0.001 # 학습률
BATCH_SIZE = 64 # 배치 크기
이제 DQN 클래스를 만들자. 에이전트의 신경망은 카트 위치, 카트 속도, 막대기 각도, 막대기 속도까지 4가지 정보를 입력받아 왼쪽으로 갈 때의 가치와 오른쪽으로 갈 때의 가치를 출력한다. 그래서 첫 번째 신경망의 입력 노드는 4개이고, 마지막 신경망의 출력 노드는 2개이다.

그림 16-2. DQN 에이전트의 인공 신경망
class DQNAgent:
def __init__(self):
self.model = nn.Sequential(
nn.Linear(4, 256),
nn.ReLU(),
nn.Linear(256, 2)
)
self.optimizer = optim.Adam(self.model.parameters(), LR)
self.steps_done = 0
딥러닝 모델들은 보통 학습 데이터 샘플이 각각 독립적이라 가정한다. 그러나 강화학습은 연속된 상태가 강한 상관관계가 있어서 학습이 어렵다는 문제점이 있다. 무작위로 가져오는 것이 아닌 연속적인 경험을 학습할 때 초반의 몇 가지 경험 패턴에만 치중하여 학습하게 된다. 그럼 최적의 행동 패턴을 찾기 어렵다. 또한 신경망이 새로운 경험을 이전 경험에 겹쳐 쓰며 쉽게 잊어버린다는 문제점도 있다.
그래서 기억하기 기능이 필요하다. 이전 경험들을 배열에 담아 계속 재학습시키며 신경망이 잊지 않게 하는 것이다. 기억한 경험들은 학습할 때 무작위로 뽑아 경험 간의 상관관계를 줄인다. 각 경험은 상태, 행동, 보상 등을 담아야 한다. 이번 예제에서는 사용하기 가장 간단한 큐 자료구조를 이용하여 이전 경험들에 관한 기억을 담을 것이다.
deque의 mexlen을 지정해주면 큐가 가득 찰 때 제일 오래된 요소부터 없어져 자연스레 오래된 기억을 잊게 해준다.
self.memory = deque(maxlen = 10000)

그림 16-3. 기억을 저장하는 큐
이제 self.memory 배열에 새로운 경험을 덧붙일 memorize() 함수를 만들자. memorize() 함수는 self.memory 배열에 현재 상태(state), 현재 상태에서 한 행동(Action), 행동에 대한 보상(Rewrard), 행동으로 인해 새로 생성된 상태(Next_state)를 한 세트로 저장한다.
def memorize(self, state, action, reward, next_state):
self.memory.append((state,
action,
torch.FloatTensor([reward]),
torch.FloatTensor([next_state])))
이제 행동을 담당하는 act() 함수를 만들자. 무작위로 숫자를 골라 앱실론 값보다 높으면 신경망이 학습하여 이렇게 행동하는게 옳다고 생각하는 쪽으로, 낮으면 무작위로 행동한다. 학습 초반에는 학습이 덜되어, 에이전트가 하는 행동에 의미를 부여하기 어렵다. 그러므로 초반에는 엡실론값을 높게 주어 최대한 다양한 경험을 해보도록 하고, 점점 그 값을 낮춰가며 신경망이 결정하는 비율을 높힌다. 이 알고리즘을 엡실론 그리디(엡실론 탐욕, Epsilon-greedy) 알고리즘이라고 한다.
def act(self, state):
eps_threshold = EPS_END + (EPS_START - EPS_END) * math.exp(-1 * self.steps_done / EPS_DECAY) # 처음에는 무작위로 행동할 확률이 높음. 그러다 점점 낮아짐.
self.steps_done += 1
if random.random() > eps_threshold:
return self.model(state).data.max(1)[1].view(1, 1) # 신경망이 결정한 행동
else:
return torch.LongTensor([[random.randrange(2)]]) # 무작위 행동
이전 경험들을 모아놨으면 반복적으로 학습해야 한다. 경험 리플레이(Experience replay)라고 하는데, 사람이 수면 중일 때 자동차 운전, 농구 슈팅 등 운동 관련 정보를 정리하여 단기 기억을 장기 기억으로 전환하는 것과 비슷하다 보면 된다.
learn() 함수는 에이전트가 경험 리플레이를 하며 학습하는 역할을 수행한다. 이 함수는 방금 만든 에이전트의 신경망(self.model)을 기억(self.memory)에 쌓인 경험을 토대로 학습시킨다. self.memory에 저장된 경험들의 수가 배치 크기보다 커지기 전까진 return으로 학습을 거르고, 경험이 충분히 쌓일 때 self.memory 큐에서 무작위로 배치 크기만큼의 무작위로 가져온다. 경험들을 무작위로 가져오면서 각 경험 샘플의 상관성을 줄일 수 있다. zip(*batch)는 (state, action, reward, next_state)가 한 세트로 모여진 하나의 배열을 state, action, reward, next_state 4개의 배열로 정리해준다.
def learn(self):
if len(self.memory) < BATCH_SIZE:
return
batch = random.sample(self.memory, BATCH_SIZE)
states, actions, rewards, next_states = zip(*batch)
각각의 경험은 상태(states), 행동(actions), 행동에 따른 보상(rewards), 그다음 상태(next_states)를 담고 있다. 모두 리스트 형태이므로 torch.cat() 함수를 이용하여 하나의 텐서로 만든다.
states = torch.cat(states)
actions = torch.cat(actions)
rewards = torch.cat(rewards)
next_states = torch.cat(next_states)
이제 에이전트의 신경망을 훈련시키자! 에이전트가 점점 발전된 행동을 하려면 가지고 있는 신경망이 주어진 상태에서 각 행동의 가치(Q)를 잘 예측하도록 학습돼야 한다. 그러므로, 현재 상테에서 에이전트가 생각하는 행동의 가치를 추출하는 작업이 필요하다!
현재 상태를 신경망에 통과시켜 왼쪽 또는 오른쪽으로 가는 행동에 대한 가치를 계산한다. gather() 함수로 에이전트가 현 상태에서 했던 행동의 가치들을 current_q에 담는다.
DQN 알고리즘 학습은 할인된 미래 가치로 누적된 보상을 극대화하는 방향으로 이루어진다. 미래 가치는 에이전트가 미래에 받을 수 있는 보상의 기대값이다. max() 함수로 다음 상테에서 에이전트가 생각하는 행동의 최대 가치를 구하여 max_next_q에 담는다. 할인은 현재 1의 보상을 받을 수 있다고 해도, 미래에도 1의 보상을 받을 때 현재의 보상을 좀 더 가치있게 보는 것을 말한다. GAMMA값을 곱해주어 에이전트가 보는 행동들의 미래 가치(max_next_q)를 20% 할인한다.
current_q = self.model(states).gather(1, actions) # 현재 상테에서 에이전트가 생각하는 행동의 가치 추출. 1 번째 차원에서 actions이 가리키는 값들을 추출한다!
max_next_q = self.model(next_states).detach().max(1)[0] # 에이전트가 본 행동들의 미래 가치
expected_q = rewards + (GAMMA * max_next_q) # 할인된 미래 가치
loss = F.mse_loss(current_q.squeeze(), expected_q) # 현재 에이전트가 생각하는 행동 가치가 할인된 미래 가치를 따라가도록 학습 진행
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()

그림 16-4. gather() 함수로 current_q가 만들어지는 과정
gym으로 게임 환경을 생성하려면 make() 함수에 원하는 게임 이름을 넣어주면 된다. 아래 코드에서 env 변수는 이제 게임 환경이 된다. 여기에 에이전트의 행동을 입력하여 행동에 따른 다음 상태와 게임 종료 여부를 출력한다.
이제 학습을 실행해보자. DQNAgent를 소환하여 agent로 인스턴스화 하자.
# 학습 준비하기
agent = DQNAgent()
env = gym.make('CartPole-v0')
score_history = [] # 학습 진행 기록하기 위해 점수 저장
# 학습 시작
for e in range(1, EPISODES+1):
state = env.reset() # 게임 시작 시 초기화된 상태를 불러오는 함수
steps = 0
게임이 끝날 때 까지 에이전트가 행동하는 것을 멈추지 않는다. 게임 진행될 때마다 env.render() 함수로 게임 화면을 띄우자. 매 턴마다 다음과 같은 상태가 진행된다.
1) 현재 게임 상태 state를 텐서로 만들고 에이전트의 행동 함수 act()의 입력으로 사용
2) 상태를 받은 에이전트는 엡실론 그리디 알고리즘에 따라 행동 action을 내뱉음
3) action 변수는 파이토치 텐서이므로 item() 함수로 에이전트가 한 행동의 번호를 추출하여 step() 함수에 입력해 넣어주면 에이전트의 행동에 따른 다음 상태(next_state), 보상(reward), 종료 여부(done)를 출력함
while True:
env.render()
state = torch.FloatTensor([state])
action = agent.act(state)
next_state, reward, done, _ = env.step(action.item()) # reward는 이상 없으면 보상 1을 줌
우리의 에이전트가 한 행동의 결과가 나왔는데 막대가 넘어져 게임이 끝났을 경우에는 -1의 처벌을 주고 이 경험을 기억하고 결과를 배우도록 한다. 학습이 진행될수록 폴대가 넘어지지 않아 게임이 끝나지 않는 방향으로 학습이 진행된다.
# 게임이 끝났을 경우 마이너스 보상주기
if done:
reward = -1
agent.memorize(state, action, reward, next_state)
agent.learn()
state = next_state
steps += 1
게임이 끝나면 done이 True가 되어 다음 코드가 실행된다. 여기서는 다음 코드로 에피소드 숫자와 점수만 표기해보자. 그리고 score_history 리스트에 점수를 담아 그래프로 나타내보자.
if done:
print("에피소드:{0} 점수: {1}".format(e, steps))
score_history.append(steps)
break
plt.plot(score_history)
plt.ylabel('score')
plt.show()
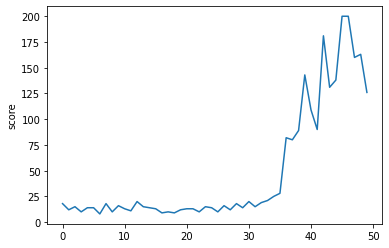
그림 16-5. DQN 에이전트의 점수 기록
Leave a comment