
[Deeplearning(pytorch)] 14. 경쟁하며 학습하는 GAN
본 포스팅은 “펭귄브로의 3분 딥러닝, 파이토치맛” 책 내용을 기반으로 작성되었습니다. 잘못된 내용이 있을 경우 지적해 주시면 감사드리겠습니다.
14-1. GAN 기초
GAN(Generative adversarial network)는 직역하면 적대적 생성 신경망이다. 단어 의미 하나하나 살펴보자.
먼저 GAN은 생성(Generative)을 하는 모델이다. CNN과 RNN은 새로운 이미지나 음성을 만들어내지 못한다. 그러나 GAN은 새로운 이미지나 음성을 창작하도록 고안되었다.
또한, GAN은 적대적(Adversarial)으로 학습한다. 적대적이라는 것은 서로 대립 관계에 있다는 것이다. 가짜 이미지를 만드는 생성자(Generator)와 이미지의 진위를 판별하는 판별자(Discriminator)가 번갈아 학습하며 경쟁적으로 학습한다.
마지막으로 GAN은 인공 신경망 모델이다. 생성자와 판별자 모두 신경망으로 되어있다.
GAN은 비지도학습 방식이다. 우리 주변의 데이터 대부분은 사실 정답이 없다. 모든 데이터를 일일이 가공하는 것이 번거롭고 어렵기 때문이다. GAN은 앞서 배운 오토인코더 처럼 비지도학습을 하여 사람의 손길을 최소화하며 학습하기 때문에 많은 이들로부터 주목을 받고 있다.
14-2. 생성자와 판별자
GAN 모델에는 무작위 텐서로부터 여러 가지 형태의 가짜 이미지를 생성하는 생성자와 진짜 이미지와 가짜 이미지를 구분하는 판별자가 존재한다. 학습이 진행되면서 생성자는 판별자를 속이기위해 점점 더 정밀한 가짜 이미지를 생성한다. 판별자는 학습 데이터에서 가져온 진짜 이미지와 생성자가 만든 가짜 이미지를 점점 더 잘 구별하게 된다. 마지막에 생성자는 진짜 이미지와 거의 흡사한 가짜 이미지를 만들게된다.
14-3. GAN으로 새로운 패션 아이템 생성하기
# 관련 모듈 임포트
import os
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from torchvision.utils import save_image
import matplotlib.pyplot as plt
# 하이퍼퍼라미터
EPOCHS = 500
BATCH_SIZE = 100
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
print("다음 장치를 사용합니다: ", DEVICE)
# Fashion MNIST 데이터셋
trainset = datasets.FashionMNIST('./.data',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
]))
train_loader = torch.utils.data.DataLoader( # 반복문에서 사용, 학습 이미지와 레이블을 튜플 형태로 반환!
dataset = trainset,
batch_size = BATCH_SIZE,
shuffle = True)
(결과) 다음 장치를 사용합니다: cpu
이제 생성자와 판별자를 구현하자. 지금까지 신경망 모델들을 모듈(nn.Module) 클래스로 정의하여 모델의 복잡한 동작들을 함수로 정의할 수 있었다. 이번에는 Sequetial 클래스를 이용할 것이다. Sequential 클래스는 신경망을 이루는 각 층에서 수행할 연산들을 입력받아 차례대로 실행하는 역할을 한다.
생성자는 실제 데이터와 비슷한 가짜 데이터를 만들어내는 신경망이다. 생성자는 정규분포로부터 64차원의 무작위 텐서를 입력받아 행렬곱(Linear)과 활성화 함수(ReLU, Tanh) 연산을 실행한다. Tanh 활성화 함수는 결과값을 -1과 1사이로 압축하는 역할을 한다. 이때 결과값은 이미지가 될 것이므로 784차원(Fashion MNIST 이미지 차원)의 텐서이다.
무작위 텐서를 입력하는 이유는 생성자가 실제 데이터의 분포를 배우기 때문이다. 즉, 그럴듯한 가짜는 수학적으로 진짜의 분포를 닮는다 할 수 있다. 이처럼 생성자는 정규분포 같은 단순한 분포에서부터 실제 데이터의 복잡한 분포를 배운다.
# 생성자(Generator)
G = nn.Sequential(
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Tanh())

그림 14-1. 생성자 모델 구조
판별자는 이미지의 크기인 784 차원의 텐서를 입력받는다. 판별자 역시 입력된 데이터에 행렬곱과 활성화 함수를 실행시킨다. 판별자는 입력된 784 차원의 텐서가 생성자가 만든 가짜 이미지인지, 실제 Fashion MNIST의 이미지인지 구분하는 분류 모델이다.
참고로 판별자에선 ReLU가 아닌 Leaky ReLU 활성화 함수를 사용한다. Leaky ReLU 활성화 함수는 양의 기울기만 전달하는 ReLU와 달리, 약간의 음의 기울기도 다음 층에 전달하는 역할을 한다. 이렇게 하면 판별자에서 계산된 기울기가 0이 아니라 약한 음수로 전환되어 생성자에 더 강하게 전달된다. GAN에서 생성자가 학습하려면 판별자로부터 기울기를 효과적으로 전달받아야 하므로 중요하다 할 수 있다.
# 판별자(Discriminator)
D = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)

그림 14-2. 판별자 모델 구조

그림 14-3. ReLU와 Leaky ReLU
이제 GAN 학습을 구현해보자. 레이블이 가짜, 진짜 2가지뿐이므로, 오차를 구하는데 이진 교차 엔트로피(binary cross entropy)를 사용하고 Adam 최적화 함수를 이용하여 학습할 것이다.
# 모델의 가중치를 지정한 장치로 보내기
D = D.to(DEVICE)
G = G.to(DEVICE)
# 이진 교차 엔트로피 오차 함수
criterion = nn.BCELoss()
# 생성자와 판별자를 최적화할 Adam 모듈
d_optimizer = optim.Adam(D.parameters(), lr=0.0002)
g_optimizer = optim.Adam(G.parameters(), lr=0.0002)
total_step = len(train_loader)
for epoch in range(EPOCHS):
for i, (images, _) in enumerate(train_loader):
images = images.reshape(BATCH_SIZE, -1).to(DEVICE)
# 진짜와 가짜 이미지에 레이블 달아주기 위해 두 레이블 텐서 정의
real_labels = torch.ones(BATCH_SIZE, 1).to(DEVICE)
fake_labels = torch.zeros(BATCH_SIZE, 1).to(DEVICE)
# 판별자가 진짜 이미지를 진짜로 인식하는 오차 계산
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
# 무작위 텐서로 가짜 이미지 생성
z = torch.randn(BATCH_SIZE, 64).to(DEVICE)
fake_images = G(z)
# 판별자가 가짜 이미지를 가짜로 인식하는 오차 계산
outputs = D(fake_images)
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
# 진짜와 가짜 이미지를 갖고 낸 오차를 더해서 판별자의 오차 계산
d_loss = d_loss_real + d_loss_fake
# 역전파 알고리즘으로 판별자 모델의 학습 진행\
d_optimizer.zero_grad()
g_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# 생성자가 판별자를 속였는지에 대한 오차 계산
fake_images = G(z)
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)
# 역전파 알고리즘으로 생성자 모델의 학습 진행
d_optimizer.zero_grad()
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# 학습 진행 알아보기
print('이폭 [{}/{}] d_loss:{:.4f} g_loss: {:.4f} D(x):{:.2f} D(G(z)):{:.2f}'.format(epoch, EPOCHS, d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item()))
(결과) 이폭 [0/500] d_loss:0.0328 g_loss: 5.7535 D(x):1.00 D(G(z)):0.03
이폭 [1/500] d_loss:0.0086 g_loss: 6.5254 D(x):1.00 D(G(z)):0.00
이폭 [2/500] d_loss:0.1043 g_loss: 5.8580 D(x):0.98 D(G(z)):0.01
이폭 [3/500] d_loss:0.2568 g_loss: 5.5040 D(x):0.93 D(G(z)):0.02
...
이폭 [497/500] d_loss:0.9463 g_loss: 1.4293 D(x):0.68 D(G(z)):0.32
이폭 [498/500] d_loss:0.8679 g_loss: 1.4807 D(x):0.73 D(G(z)):0.34
이폭 [499/500] d_loss:0.7914 g_loss: 1.7547 D(x):0.69 D(G(z)):0.24
이제 결과물을 시각화 해보자.
# 생성자가 만든 이미지 시각화하기
z = torch.randn(BATCH_SIZE, 64).to(DEVICE)
fake_images = G(z)
for i in range(10):
fake_images_img = np.reshape(fake_images.data.cpu().numpy()[i], (28, 28))
plt.imshow(fake_images_img, cmap = 'gray')
plt.show()
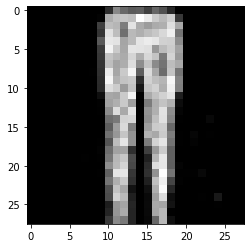
그림 14-4. 코드 결과

그림 14-5. 코드 결과

그림 14-6. 코드 결과

그림 14-7. 코드 결과

그림 14-8. 코드 결과
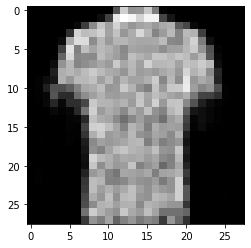
그림 14-9. 코드 결과
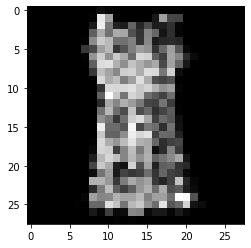
그림 14-10. 코드 결과

그림 14-11. 코드 결과

그림 14-12. 코드 결과
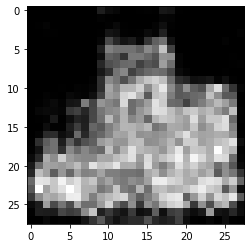
그림 14-13. 코드 결과
CNN 등 더 복잡한 모델을 사용하면 훨씬 높은 해상도의 이미지를 생성할 수 있다.
Leave a comment